PDF Parsing in Node.js: A Complete Technical Guide (June 2026)
You install pdf-parse npm, follow the pdf-parse documentation, and extract text from a clean PDF in about ten lines of code. Then you try it on a real document from your pipeline: a multi-page financial report, a scanned legal contract, or a dense medical record with tables and footnotes. The text c


You install pdf-parse npm, follow the pdf-parse documentation, and extract text from a clean PDF in about ten lines of code. Then you try it on a real document from your pipeline: a multi-page financial report, a scanned legal contract, or a dense medical record with tables and footnotes. The text comes back scrambled, tables collapse into flat strings with no column structure, and scanned pages return empty because pdf-parse has no OCR layer. This is the expected behavior of most javascript pdf library tools including pdf2json, pdf.js, pdf-parse js, pdf-parse typescript, pdf-parse-new, and nearly every pdf parser python option you'll find on npm or pdf parser python github. These libraries extract text; they do not preserve layout, reading order, or table structure. If your use case stops at pulling raw text from digital-native PDFs, pdf parse works fine. If you need to parse pdf python documents with complex formatting, parse pdf c# projects with nested tables, parse pdf java files with multi-column layouts, or handle any pdf parsing tool scenario where structure matters, you need something that treats layout as a first-class input. This guide walks through how to parse a pdf with pdf-parse and similar tools, where each library breaks down in production, and what changes when you move to a vision-first parser that returns every extracted field with a confidence score, a bounding box, and a word-level citation back to the source page.
TLDR:
- pdf-parse extracts text and metadata from digital PDFs but fails on scanned docs, tables, and layouts
- Requires Node.js 20.16.0+, 22.3.0+, 23.0.0+, or 24.0.0+ and only runs server-side in Next.js
- Multi-column layouts collapse into flat text streams with no structural markers preserved
- pdf2json, pdfjs-dist, pdfreader, and pdf-parse-new each optimize for different constraints
- Unsiloed AI uses vision models that preserve layout and return confidence scores with citations
What Is pdf-parse and When Should You Use It
pdf-parse is a Node.js package that extracts raw text from PDF files using pdf.js under the hood. It reads a PDF buffer and returns a result object containing the full text string, page count, and metadata. Setup is minimal: pass a buffer to the parse function and get structured output back synchronously.
It works well for straightforward use cases: extracting text from digital-native PDFs, batch processing documents in a Node.js pipeline, or pulling metadata like author and creation date. When your PDFs are clean and text-based, pdf-parse handles the job with very little configuration.
The library has real limits worth knowing before you build around it:
- Scanned documents with no embedded text layer return empty strings since pdf-parse has no OCR capability.
- Table structure is lost entirely; the extracted text reflects reading order as stored in the PDF, which often scrambles multi-column layouts.
- Complex formatting like nested lists, footnotes, and headers collapses into a flat text stream with no semantic markers.
If your pipeline needs layout preservation, table extraction, or scanned document support, pdf-parse alone will not get you there. For production pipelines where structure and accuracy matter, a purpose-built parsing layer handles those cases more reliably.
Installing pdf-parse in Your Node.js Project
Install the package using whichever package manager your project uses:
npm install pdf-parse
pnpm add pdf-parse
yarn add pdf-parse
bun add pdf-parse
Node.js version compatibility is worth confirming before you commit. Per the pdf-parse npm documentation, supported versions are 20.16.0+, 22.3.0+, 23.0.0+, and 24.0.0+. Versions 21.x, 19.x, and anything earlier are unsupported, so check your runtime before building production pipelines around this library.
For command-line usage, a global install works:
npm install -g pdf-parse
Basic Text Extraction with pdf-parse
The v2 API uses a PDFParser class constructor instead of a bare function call. All parsing is asynchronous, so you'll work with promises or async/await throughout.
Parsing a Local File
import fs from "fs/promises";
import PDFParser from "pdf-parse/lib/pdf-parse.js";
async function extractText(filePath) {
const buffer = await fs.readFile(filePath);
const data = await PDFParser(buffer);
console.log(data.text); // full extracted text string
console.log(data.numpages); // total page count
console.log(data.info); // PDF metadata object
console.log(data.version); // pdf.js version used internally
}
extractText("./document.pdf");
The result object's text property concatenates all page content into a single string. Page breaks are not preserved; if you need per-page text, pass a custom pagerender function. For pipelines that need PDF to JSON conversion, the raw text string is the starting point before further parsing.
Parsing from a Remote URL
Fetch the PDF into a buffer first, then pass it to the parser the same way:
import PDFParser from "pdf-parse/lib/pdf-parse.js";
async function extractFromUrl(url) {
const response = await fetch(url);
const arrayBuffer = await response.arrayBuffer();
const buffer = Buffer.from(arrayBuffer);
const data = await PDFParser(buffer);
return data.text;
}
Accessing Metadata
The info field returns whatever the PDF's document dictionary contains. Common fields include Title, Author, CreationDate, and Producer, though these are set by the authoring tool and may be empty.
const data = await PDFParser(buffer);
const { Title, Author, CreationDate } = data.info;
Per-Page Text Extraction with getText()
To intercept text on a page-by-page basis, supply a pagerender callback in the options object:
const pages = [];
const options = {
pagerender: (pageData) => {
return pageData.getTextContent().then((content) => {
const pageText = content.items.map((item) => item.str).join(" ");
pages.push(pageText);
return pageText;
});
},
};
const data = await PDFParser(buffer, options);
console.log(pages); // array of per-page text strings
This gives you individual strings per page before they're concatenated into data.text. For pipelines that only need the full document string, skip the callback and read data.text directly.
Extracting Metadata and Document Information
Beyond raw text, pdf-parse exposes a metadata object on every parsed result. This gives you access to document-level properties that are often as useful as the content itself.
Here is what a typical metadata extraction looks like in practice:
const pdf = require('pdf-parse');
const fs = require('fs');
async function extractMetadata(filePath) {
const dataBuffer = fs.readFileSync(filePath);
const data = await pdf(dataBuffer);
return {
pageCount: data.numpages,
pdfVersion: data.info.PDFFormatVersion,
author: data.info.Author,
title: data.info.Title,
created: data.info.CreationDate,
modified: data.info.ModDate,
textLength: data.text.length
};
}
Key Fields Returned
numpagesreturns the total page count, which is useful for pagination logic or filtering out documents that exceed a processing threshold.infocontains standard PDF metadata includingAuthor,Title,Creator,Producer,CreationDate, andModDate.metadataholds XMP metadata when present, which some publishing tools embed alongside the standard info object.versionreflects the PDF spec version the parser used internally.
Not every PDF populates these fields. Scanned documents and programmatically generated reports frequently omit author and title entries entirely, so treat all metadata fields as optional in your application logic.
Working with Images and Tables in PDFs
PDFs frequently store images as raw binary streams and tables as visually formatted text with no semantic structure. Standard text extraction treats both as undifferentiated content, producing garbled output or silent data loss.

Extracting Images
Most Node.js parsers cannot extract embedded images directly. For image extraction, you typically need lower-level tools like pdf-lib or native bindings to libraries such as MuPDF. Once extracted, images require separate processing via OCR or a vision model to produce usable text.
Parsing Tables
Table parsing is where most JavaScript PDF libraries fall short. Without layout awareness, a three-column table collapses into a single text stream with no column boundaries preserved. Approaches include:
- Coordinate-based reconstruction, where you group text spans by their Y-axis position and infer column boundaries from X-axis gaps, works for simple tables but breaks on merged cells or spanning headers.
- Heuristic line detection, which looks for horizontal whitespace gaps between rows, degrades quickly on dense financial or legal tables.
- Vision-based parsing treats the page as an image and identifies table structure visually, which handles irregular layouts but adds latency and requires a capable model.
For production pipelines handling contracts, financial statements, or medical records, coordinate-based approaches rarely hold up at scale. Vision-first parsers that preserve bounding boxes and reading order produce more reliable structured output across varied document types.
Browser and Serverless Deployment
Running pdf-parse in a browser or serverless environment requires a different setup than a standard Node.js server. The library depends on Node.js built-ins like fs and Buffer, which are unavailable in browser contexts and may need explicit configuration in serverless runtimes like Next.js Edge or Vercel Functions.
For Next.js projects, keep pdf-parse in server-side code only. Place your parsing logic inside API routes (/pages/api/) or Server Components, never in client components. You can also configure your next.config.js to exclude the library from client bundles:
module.exports = {
webpack: (config) => {
config.externals = [...(config.externals || []), 'pdf-parse'];
return config;
},
};
For browser-based PDF display and text extraction, PDF.js is the appropriate alternative, as it runs entirely client-side without Node.js dependencies.
Key considerations by deployment target:
- Vercel Serverless Functions support pdf-parse with no extra config, but keep an eye on cold start times when processing large files.
- Edge Functions lack Node.js built-in access entirely, so pdf-parse will fail silently or throw at runtime.
- AWS Lambda works, but function package size limits may require bundling carefully to stay under the 250MB unzipped threshold.
Comparing pdf-parse with Similar Packages
Each JavaScript PDF library optimizes for a different constraint. Map your actual requirements against what each package handles well before committing to one.
| Library | Best For | Key Tradeoff |
| pdf-parse | Simple text extraction from digital-native PDFs | No OCR, no layout, flat text only |
| pdf2json | JSON output with coordinate data and basic layout | Heavier output, less maintained |
| pdfjs-dist | Full page display, browser support, structural analysis | Large bundle (~3MB), complex API |
| pdfreader | Streaming large files row by row | Less community support, minimal features |
| pdf-parse-new | Performance optimization with parallel processing | Newer, smaller community, still maturing |
Choose pdf-parse when your use case is purely text extraction from clean, digitally generated PDFs and you want zero native dependencies, or review document parsing software options for more complex needs. Its API surface is small and setup is fast.
pdfjs-dist fits when you need browser-side page display or low-level page structure access, though bundle size and API complexity become real costs if you only need extracted text.
pdf2json adds coordinate metadata that can help reconstruct basic reading order, but sees less active maintenance. pdfreader handles streaming well for large files where loading a full buffer into memory is a concern. pdf-parse-new targets parallel processing performance, but its community and documentation remain thinner than the original package.
Common Pitfalls and Troubleshooting
A few failure modes come up repeatedly in production, and most have a direct fix.
Worker path resolution breaks in bundled environments like webpack or esbuild, which rewrite file paths at build time. The library resolves its internal pdf.js worker using a relative path that assumes a standard node_modules layout. When that layout changes, parsing silently fails or throws a module resolution error. Pointing the worker path explicitly before parsing resolves it in most cases.
Encrypted and password-protected PDFs return an error instead of text. pdf-parse has no decryption support, so protected files need to be unlocked upstream before they reach the parser.
Memory spikes are common with large multi-page files since the entire buffer loads into memory before parsing begins. For files above a few hundred pages, consider splitting documents upstream or streaming pages individually via the pagerender callback.
A few other issues worth knowing:
- Calling pdf-parse in a test environment that tries to load test files from a
test/directory can trigger an unintended file read. The pdf-parse GitHub repository documents this behavior; import frompdf-parse/lib/pdf-parse.jsdirectly to avoid it. - Some PDFs embed fonts without a Unicode mapping, producing garbled characters in
data.text. The parser cannot recover those glyphs without OCR. - Zero-page count results (
numpages: 0) typically indicate a corrupt or non-standard PDF structure, not a parsing bug.
Vision-First Parsing for Production Document Pipelines
When pdf-parse and similar text-extraction libraries hit their limits, the failure mode is consistent: multi-column layouts collapse into scrambled reading order, tables lose their structure, and scanned pages return nothing at all. These aren't edge cases in production document pipelines; they're the norm for financial reports, legal contracts, and healthcare records.
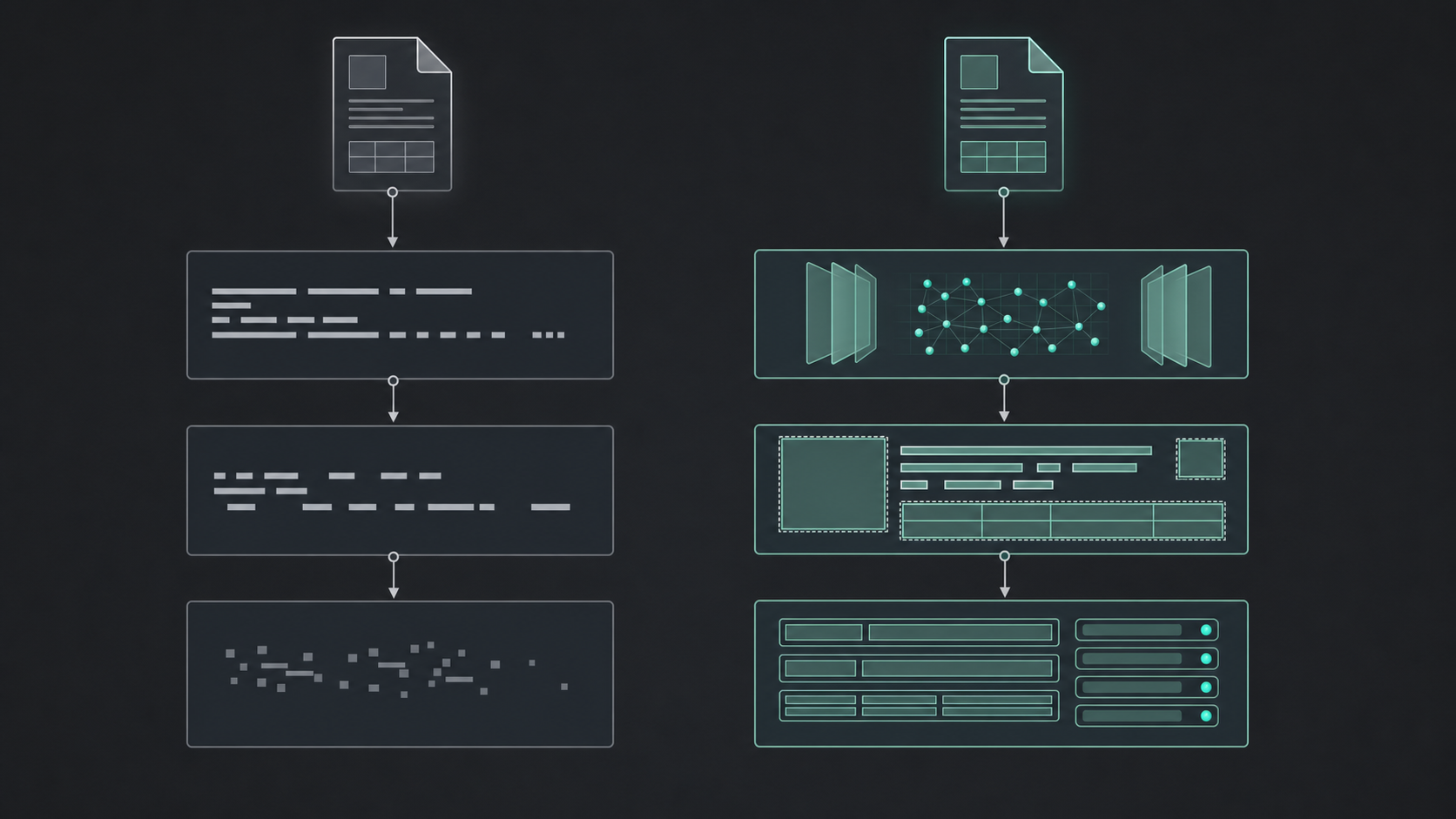
Unsiloed AI parses documents with a vision model that preserves layout and reading order before any text extraction occurs. Every extracted field returns a confidence score, a bounding box, and a word-level citation back to the source page, giving downstream systems the grounding they need to produce accurate, auditable outputs through structured document data extraction.
For teams where extraction accuracy directly affects decisions, that traceability is what separates a working pipeline from one that quietly produces wrong answers. For a deeper look at how parsers differ, see the document parser tools comparison.
Final Thoughts on pdf-parse for Node.js Projects
This library handles basic text extraction with almost no configuration, which is exactly what you need for digital-native PDFs in a straightforward pipeline. The constraints become real when your documents contain tables, scanned pages, or complex layouts where structure matters as much as content. If you're building document processing that feeds downstream AI systems, book a demo to see how vision-first parsing returns bounding boxes and confidence scores alongside extracted text.
FAQ
Can I use pdf-parse for scanned PDFs?
No. pdf-parse extracts text only from digital-native PDFs with embedded text layers; scanned documents with no embedded text return empty strings because the library has no OCR capability. For scanned documents, you need a parser with vision-based OCR or a preprocessing step that adds the text layer before extraction.
How do I extract table structure from PDFs in Node.js?
pdf-parse and most JavaScript PDF libraries cannot preserve table structure because they output flat text streams with no layout awareness. Coordinate-based reconstruction works for simple single-page tables but breaks on merged cells or spanning headers. For production pipelines handling financial statements or contracts, vision-first parsers that return bounding boxes and reading order produce more reliable structured output across varied document types.
Does pdf-parse work in Next.js API routes?
Yes. Place pdf-parse logic inside Next.js API routes (/pages/api/) or Server Components only, never in client components. You can also configure next.config.js to exclude the library from client bundles with config.externals. Edge Functions lack Node.js built-in access entirely, so pdf-parse will fail at runtime in that environment.
What is the difference between pdf-parse and pdfjs-dist?
pdf-parse is lighter and simpler for pure text extraction, with minimal setup and no browser dependencies. pdfjs-dist provides full page display, browser support, and structural analysis but adds ~3MB to your bundle and exposes a more complex API. Choose pdf-parse when you only need extracted text and want zero configuration overhead; use pdfjs-dist when you need page display or low-level page structure access.
How do I choose a document processing solution with low error rates?
Error rates depend on document structure and parser capabilities. Text-only parsers like pdf-parse work well for clean, digitally generated PDFs but lose structure and reading order on complex layouts. For production pipelines where accuracy matters, vision-based parsers that preserve layout and return confidence scores per field with word-level citations reduce errors by grounding every extraction in verifiable source data.