
Document Data Extraction: A Technical Guide for Modern Applications (April 2026)


Every time you feed a complex document into your document data extraction ai, you're gambling on whether the output will preserve table structures, maintain reading order, and map fields to the right values. Simple forms work fine, but throw in nested tables, rotated text, or multi-page schedules and the whole pipeline breaks. What you need is an extraction approach that understands spatial layout before it starts pulling text, so table boundaries and hierarchical relationships survive the conversion intact.
TLDR:
- Document data extraction converts unstructured files into structured data for systems and AI agents.
- Vision-first models outperform OCR by 15-20% on complex tables and multimodal layouts.
- Schema-based extraction returns deterministic JSON with confidence scores and word-level bounding boxes.
- Production workflows require async processing, confidence thresholds, and field-level traceability.
- Unsiloed AI processes millions of pages weekly for Fortune 150 banks using dual-stream vision models.
What Document Data Extraction Is and Why It Matters
Document data extraction is the process of pulling structured, machine-readable information out of unstructured source files, whether that's a scanned invoice, a dense legal contract, or a multi-page financial report. The goal is straightforward: take raw document content and make it usable by downstream systems, databases, or AI agents.
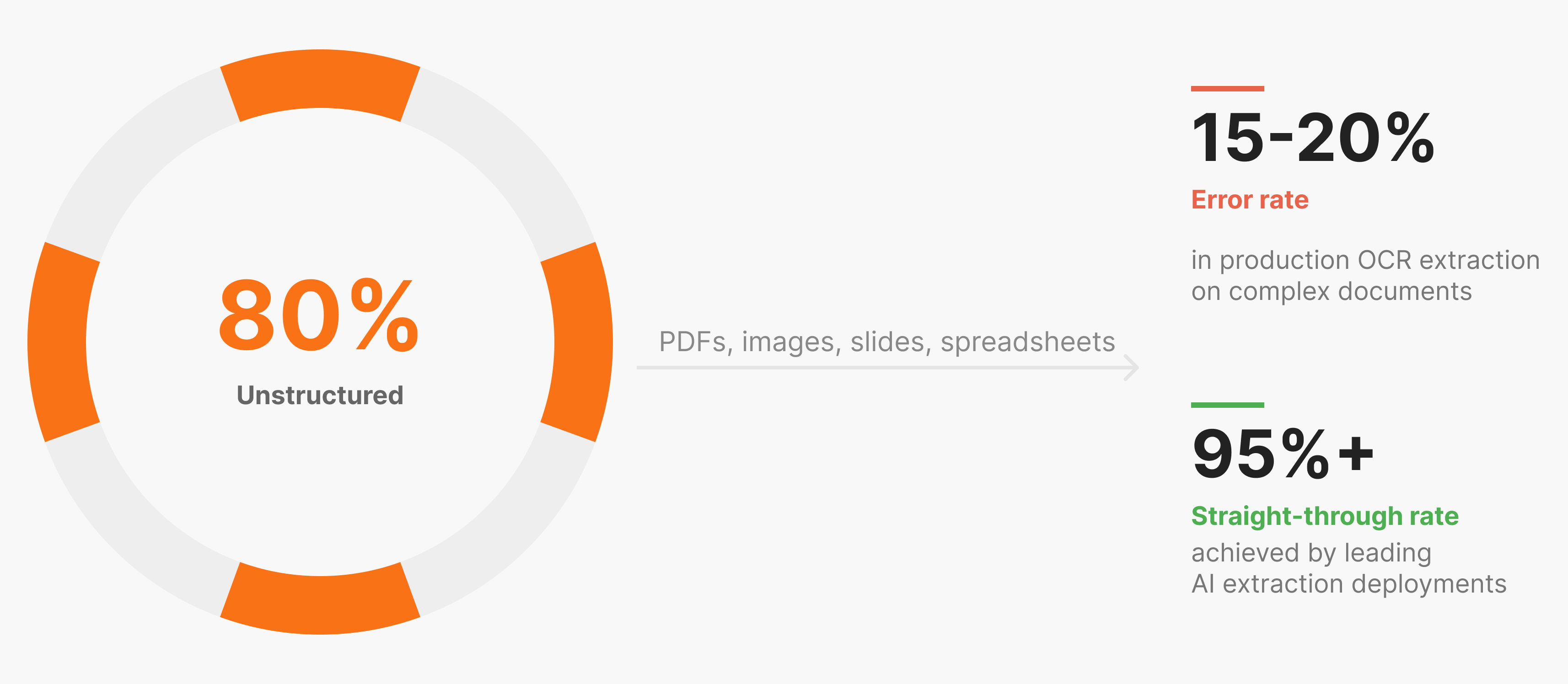
The scale of the problem is hard to ignore. Over 80% of enterprise data is unstructured, locked inside PDFs, images, spreadsheets, and slides that no database can query directly.
Manual extraction does not scale, with error rates costing millions annually in lost productivity, and the cost of errors in high-stakes domains like finance or healthcare is steep.
Getting this right is infrastructure-level work.
Technical Approaches to Document Data Extraction
Several distinct technical approaches exist for pulling data out of documents, each with real tradeoffs in accuracy, flexibility, and production reliability.
Rule-Based Extraction
Early extraction systems relied on fixed templates and positional rules. If an invoice always had the vendor name in the top-left corner, you could hardcode that lookup. These systems are fast but brittle. Change the form layout and the whole pipeline breaks.
OCR-Based Extraction
Optical character recognition converts scanned images into raw text. Standard OCR works reasonably well for clean, simple documents, but struggles in production. Dense tables, rotated text, mixed fonts, and multi-column layouts all degrade output quality. Traditional OCR produces 15-20% information extraction errors in production environments, which compounds fast at scale.
ML-Based Extraction
ML approaches train models to recognize document structure across document types. Most still treat documents as text sequences, losing spatial and visual context in the process.
Vision-First AI Extraction
The most capable approach treats documents as visual objects first. Vision models analyze layout, reading order, table boundaries, and image content simultaneously, instead of converting a PDF to text and parsing afterward.
Approach | Layout Awareness | Table Accuracy | Production Reliability |
|---|---|---|---|
Rule-based | None | Low | Brittle |
Standard OCR | Minimal | Poor | Inconsistent |
ML-based | Partial | Medium | Moderate |
Vision-first AI | Full | High | Deterministic |
Simple, uniform documents can sometimes get by with OCR. Anything with dense tables, irregular formatting, or mixed content requires a vision-aware approach to hold up reliably.
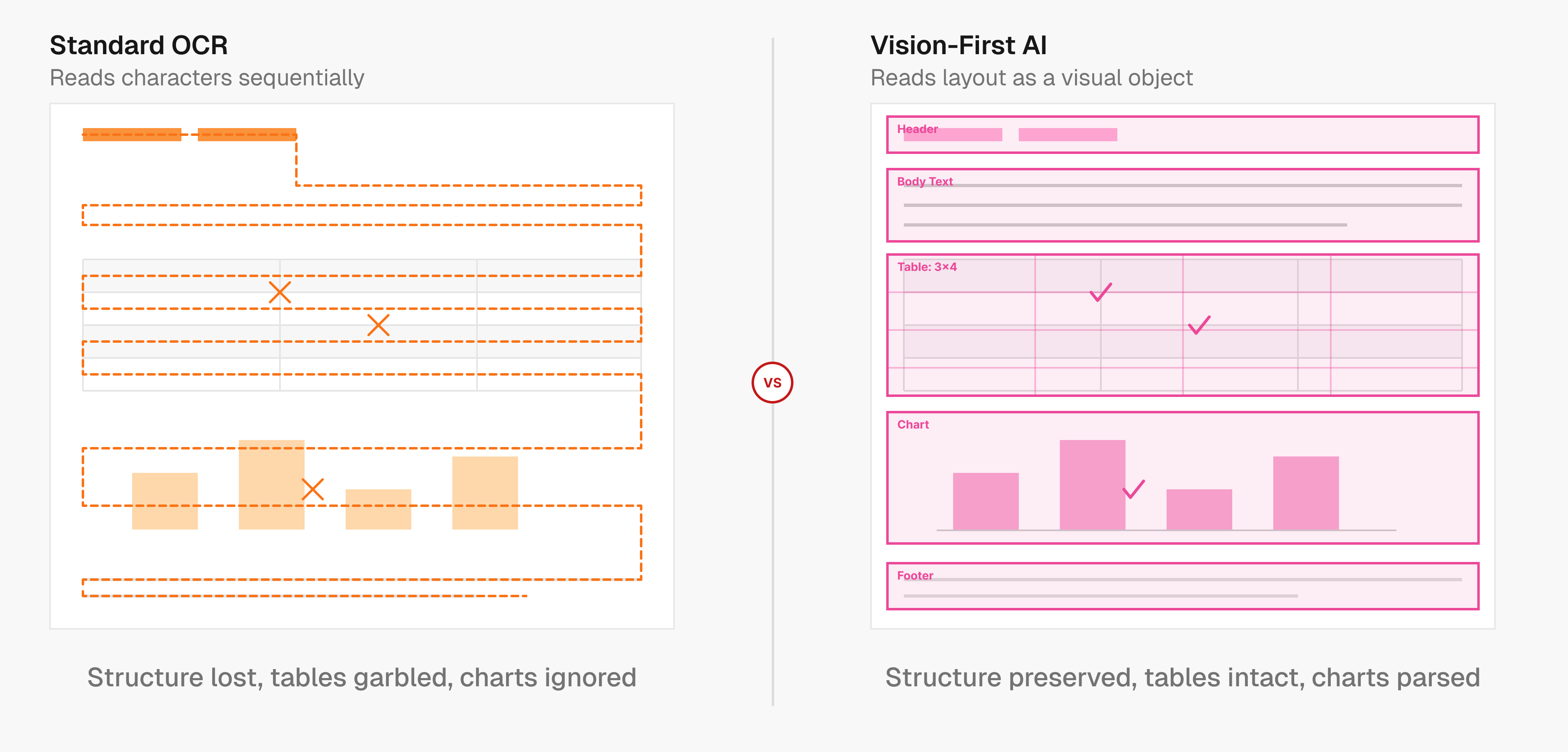
How Vision Models Outperform OCR for Complex Documents
Standard OCR reads documents the way a scanner does: left to right, top to bottom, character by character. That works fine for a single-column text document. Feed it a financial statement with nested tables, a medical form with checkboxes and sidebars, or a slide deck mixing charts with prose, and it starts losing structural information that can't be recovered downstream.
The core issue is that OCR discards layout before your pipeline ever sees the output.
Vision models take a different approach. Instead of converting pixels to characters first, they analyze the full page as a visual object, identifying where tables begin and end, how columns relate to headers, and how reading order flows across a complex layout. This structural understanding happens before any text gets extracted.
Why Tables Break OCR Pipelines
Tables are the clearest example of where character-level reading fails. A merged cell, a rotated header, or a table spanning two pages can cause OCR to serialize content in the wrong order, collapse rows, or drop values entirely. Vision models trained on document layouts recognize table boundaries as spatial objects, preserving row-column relationships even when formatting is irregular.
Multimodal Documents Need Multimodal Parsing
Real-world documents mix text, images, charts, formulas, and diagrams on the same page. OCR ignores or mangles non-text elements. A vision-first system handles each element type with the appropriate extractor, outputting clean Markdown or JSON that reflects the actual document structure, so nothing meaningful gets dropped.
Schema-Based Extraction for Deterministic Outputs
Schema-based extraction works on a simple contract: you define exactly what fields to pull, what types they should be, and the system returns structured JSON matching your specification every time.
You describe the target data using a JSON schema, specifying field names, types (string, number, boolean, array), and descriptions that guide the model toward the right content. The extraction engine locates each field, returns the value, and attaches a confidence score and word-level bounding box so every output traces back to its source.
{
"type": "object",
"properties": {
"invoice_number": { "type": "string", "description": "Invoice number" },
"total_amount": { "type": "number", "description": "Total amount due in USD" }
},
"required": ["invoice_number", "total_amount"],
"additionalProperties": false
}
Setting additionalProperties: false is what keeps outputs deterministic. Without it, a model can return unexpected fields that break downstream systems expecting a fixed structure.
Confidence Scores and Bounding Boxes
Confidence scores separate usable extractions from ones needing review. A score near 1.0 signals high certainty. Scores below 0.7 flag outputs warranting human verification before moving downstream, which matters in finance or legal workflows where a wrong value carries real consequences.
Bounding boxes map each extracted value back to pixel coordinates on the page, so discrepancies can be audited visually without re-reading the full document.
Accuracy Benchmarks and Production Requirements
Advertised accuracy numbers rarely survive contact with production. A system claiming 99% accuracy on clean, structured invoices may drop to 70% or lower on scanned documents with inconsistent formatting, multi-column layouts, or handwritten annotations. The document type matters as much as the method.
AI-powered extraction can reach up to 99% accuracy on structured documents with consistent layouts. That ceiling drops on dense financial filings, mixed-content medical forms, or legal contracts where clause boundari
What separates high-performing systems in production is how they handle the hard cases, not the easy ones. Organizations implementing AI document processing report 20-40% productivity improvements within the first year, with leading deployments achieving 95%+ straight-through processing rates.
not the easy ones.
Confidence scoring is what makes accuracy measurable at runtime. A well-designed system flags low-confidence extractions for human review so errors get caught before they propagate downstream, instead of treating every output as equally reliable.
Industry Applications Across Finance, Legal, and Healthcare
Each industry has its own failure modes when extraction goes wrong.
Finance
Financial documents pack dense tables, footnotes, and multi-page schedules into formats that break generic parsers. SEC filings like 10-Ks mix narrative prose with structured ownership tables and segment financials. Extracting line items, XBRL-tagged values, or shareholder breakdowns requires layout-aware parsing that preserves row-column relationships across pages.
Legal
Contracts present different extraction challenges. The work is clause-level: identifying termination conditions, obligation dates, and counterparty names within dense, non-tabular text. Missing a single clause or misreading a date has direct legal consequences, so confidence scoring and source citations are not optional features here.
Healthcare
Clinical documents combine structured fields, free-text notes, and images on the same form. Lab reports, insurance authorizations, and intake records each carry different schemas. Extraction systems need to handle layout variation across form types while keeping outputs auditable for downstream compliance requirements.
Building Production Document Workflows with APIs
Production document workflows built on APIs follow a consistent pattern: submit a job, poll for completion, then route the output. The async model exists because large, multi-page documents take time, and blocking a thread while waiting is not viable at scale.
A minimal production loop looks like this: POST to /v2/extract with your document and schema, capture the job_id, then poll /extract/{job_id} until status returns completed. From there, route the structured JSON wherever it needs to go.
Where most implementations break down is in how they handle confidence scores. Treating all outputs equally is a mistake. A practical threshold pattern:
- Score 0.9+: pass directly to downstream systems
- Score 0.7 to 0.9: flag for async review before committing
- Score below 0.7: route to manual verification queue
For RAG pipelines, the parsed embed field from each chunk goes straight to your embedding step. Bounding boxes make disagreements auditable without re-reading source documents. For database writes or workflow triggers, extracted JSON maps cleanly to typed fields as long as your schema enforces additionalProperties: false from the start.
How Unsiloed AI Approaches Document Data Extraction
The extraction architecture at Unsiloed AI starts from one assumption: documents are visual objects first, not text sequences. A dual-stream vision model captures both semantic content and spatial layout simultaneously, so table structures, reading order, and hierarchical relationships survive parsing intact without getting flattened before your pipeline sees them.
Schema-based extraction sits on top of that foundation. You define a JSON schema, and every extracted field returns with a confidence score, page reference, and word-level bounding box. Nothing is inferred beyond what the schema specifies. That traceability makes outputs auditable in domains like finance and legal where errors carry real cost.
Unsiloed AI processes millions of pages weekly for Fortune 150 banks, mortgage servicers, and NASDAQ-listed enterprises, consistently outperforming other extraction solutions on public benchmarks. Reach out at hello@unsiloed-ai.com to see how it handles your documents.
Final Thoughts on Choosing Document Extraction Methods
Document data extraction becomes infrastructure the moment your business depends on it running reliably without manual cleanup. OCR works until it doesn't, rules break when formats change, and text-only ML models lose the spatial information that keeps tables coherent. Vision models cost more upfront but save you from building error-correction workflows downstream. Book a demo to see whether your documents need simple OCR or something that actually preserves layout.
FAQ
Can I extract data from PDFs without traditional OCR?
Yes, vision-first AI extraction processes documents as visual objects instead of converting them to text first. This approach preserves layout, table structures, and reading order that standard OCR discards, making it more reliable for complex financial statements, legal contracts, and medical forms.
What's the difference between rule-based and AI document data extraction?
Rule-based extraction relies on fixed templates and positional rules that break when document layouts change, while AI document data extraction uses vision models to understand document structure across varying formats. Rule-based systems work only for identical forms, whereas vision models handle layout variation in production.
How accurate is AI-powered document data extraction in production?
AI extraction reaches up to 99% accuracy on structured documents with consistent layouts, but accuracy drops on dense financial filings or mixed-content forms. Production reliability depends on confidence scoring that flags uncertain extractions for review instead of treating all outputs as equally reliable.
Best PDF data extraction tool for tables and nested data?
Vision-aware extraction systems outperform traditional PDF data extraction tools on complex tables because they recognize table boundaries as spatial objects instead of serializing text character-by-character. Look for tools that preserve row-column relationships and provide confidence scores with bounding boxes for verification.
What is schema-based extraction for document data?
Schema-based extraction uses JSON schemas to define exactly which fields to pull from documents, returning structured outputs that match your specification every time. Each extracted value includes a confidence score and word-level bounding box that traces back to the source, making outputs deterministic and auditable for downstream systems.