
Unsiloed Achieves #1 Rank on olmOCR-Bench

Published by Unsiloed AI | May 2026
Introduction
Optical Character Recognition (OCR) remains the foundation of any document AI pipeline. Whether you are extracting data from invoices, parsing academic papers, or digitizing handwritten forms, the accuracy of your OCR layer determines the ceiling for everything downstream.
The olmOCR-Bench benchmark, published by Allen AI (allenai/olmocr), is a rigorous, reproducible evaluation of how well modern AI models handle real-world OCR challenges. It runs 8,413 unit tests across 1,403 PDF pages, covering math equations, complex tables, headers/footers, multi-column reading order, long/tiny text, and old scans.
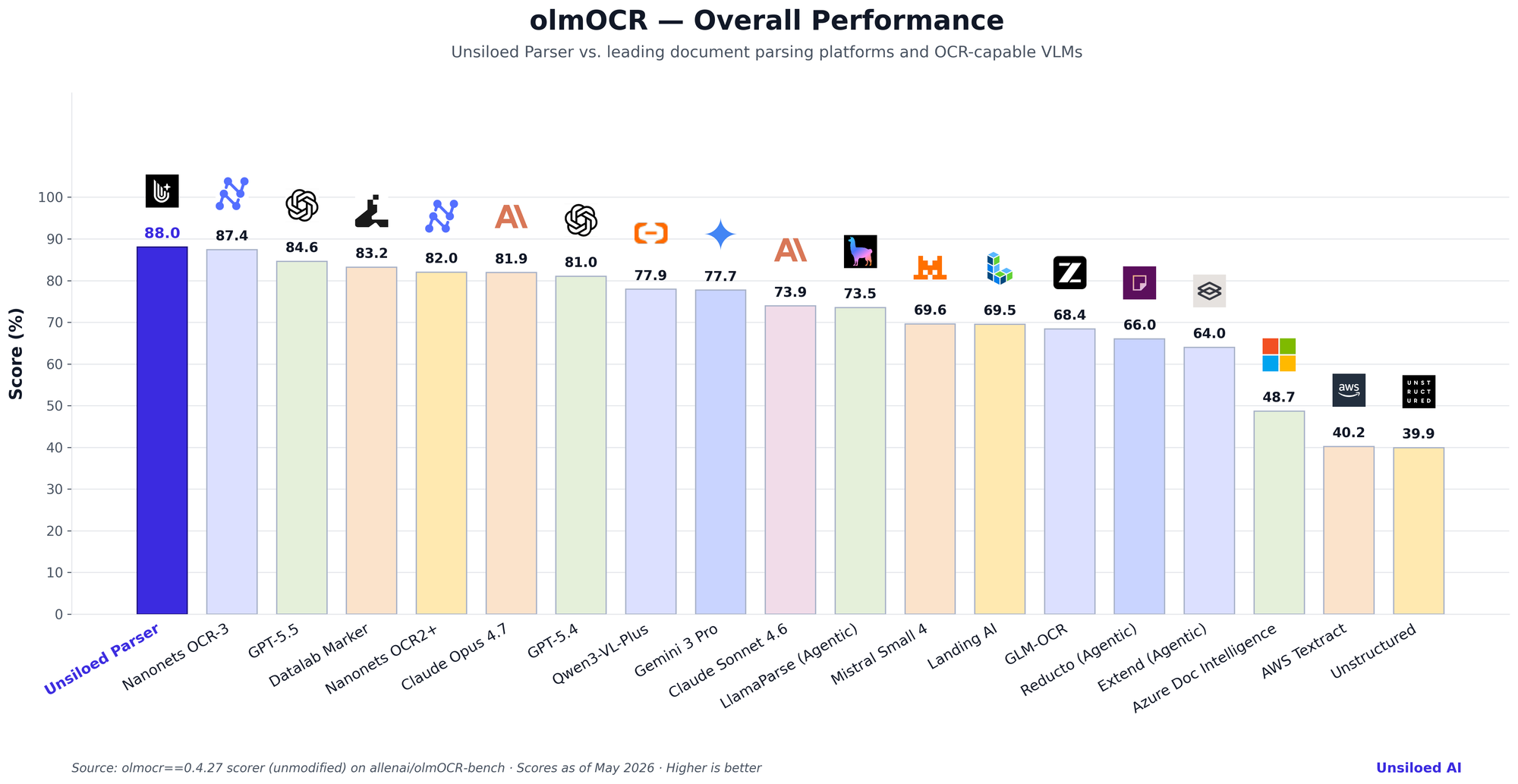
We compared Unsiloed Parser against 18 other widely-used OCR services and document-AI platforms. Unsiloed Parser was evaluated by us on olmOCR-Bench using the unmodified upstream scorer and other services were also independently measured on the exact same harness (GPT-5.5, Claude Opus 4.7, LlamaParse (Agentic), Reducto (Agentic), Extend (Agentic), Landing AI, Azure Document Intelligence, AWS Textract and Unstructured. Full report and per-vendor runner code to reproduce the scores is at github.com/Unsiloed-AI/unsiloed-olmocr-benchmark).
The scores for Nanonets OCR-3 and Nanonets OCR2+ couldn't be verified independently and was sourced from publicly-published olmOCR-Bench results, all run against the same upstream scorer, same dataset, and the same 7-category JSONL test files (verified md5-identical to our snapshot). Unsiloed Parser leads at 88.0 on the deterministic pass-rate.
We also re-evaluated our failures using an LLM-as-a-Judge protocol (explained later in the post), which lifts the corrected score to 94.8 when semantically-equivalent rewrites are no longer counted as failures. Here are the results.
What olmOCR-Bench Tests
The benchmark evaluates seven document-content categories using pass/fail unit tests across 1,403 single-page PDFs sourced from arXiv, the Internet Archive, and curated internal collections:
Math on Research Papers (ArXiv Math)
Can the model accurately convert complex mathematical notation like fractions, integrals, summation symbols, matrices into KaTeX-renderable LaTeX on clean, typeset research papers? One of the most demanding OCR tasks and a strong differentiator between models.
Math on Scanned / Historical Pages (Old Scans Math)
The same KaTeX-renderable-LaTeX requirement, but applied to mathematical content on scanned, low-DPI, or handwritten pages, the hardest math sub-task in the benchmark.
Table Structure Preservation (Tables)
Documents are full of tables with merged cells, nested headers, and irregular layouts. The benchmark tests whether models maintain logical structure, not just extract the text, but understand which cell belongs to which row and column.
Header & Footer Handling (H&F)
Page numbers, footnotes, running headers, and section markers create noise. The benchmark checks whether models correctly suppress these elements without mixing them into body text.
Multi-Column Reading Order (Multi-Col)
Academic papers, newspapers, and reports often use multi-column layouts. The benchmark evaluates whether models read text in the correct semantic order.
Long / Tiny Text (Long/Tiny)
Footnotes, captions, fine print, content that's small or runs across many lines. Tests OCR fidelity on edge cases that production documents are full of.
Degraded / Historical Scans (Old Scans)
Low-quality, low-DPI, or otherwise degraded images. The hardest category by a wide margin.
How We Ran the Benchmark
The bar chart and per-category breakdown below combine two sources, both scored with the same olmocr==0.4.27 benchmark code on the same allenai/olmOCR-bench dataset.
Full benchmark results were obtained for Unsiloed Parser plus other services.
- Unsiloed Parser
- GPT-5.5 — OpenAI flagship VLM,
full_no_document_anchoringprompt - Claude Opus 4.7 — Anthropic flagship via Vertex AI
- LlamaParse (Agentic) — LlamaIndex's premium
parse_page_with_agentmode - Reducto (Agentic) — Reducto's premium agentic pipeline (text + table + figure agents, with
advanced_chart_agent=true), each scope receiving the samefull_no_document_anchoringprompt - Extend (Agentic) — Extend AI's Parse API with
parse_performanceengine, agentic text + tables, formulas, and advanced charts enabled - Landing AI — Agentic Document Extraction (default tier)
- Azure Document Intelligence —
prebuilt-layout - AWS Textract —
AnalyzeDocument(synchronous) - Unstructured —
partition(hi_resstrategy, legacy endpoint)
For each commercial service the highest-quality publicly-documented configuration the vendor exposes was used i.e. premium / agentic / hi-res modes where they exist, full layout + table + math features turned on, and the vendor's flagship model where a choice was offered. Outputs were post-processed identically before scoring, so no system was disadvantaged by a default-only configuration. Full per-service config and runner source code is committed to our open-source benchmarks repo at github.com/Unsiloed-AI/unsiloed-olmocr-benchmark.
Unsiloed Parser leads the field at 88.0 on the deterministic pass-rate, with a +0.6-point gap over the next closest competitor (Nanonets OCR-3 at 87.4) and +3.4 points over the next closest vision-LLM (GPT-5.5 at 84.6). Among dedicated document-AI services in our in-house run, Unsiloed Parser leads LlamaParse Agentic by 14.5 points, Landing AI by 18.5 points, and Azure DI / Textract / Unstructured by 39 points or more.
Per-Category Score Breakdown
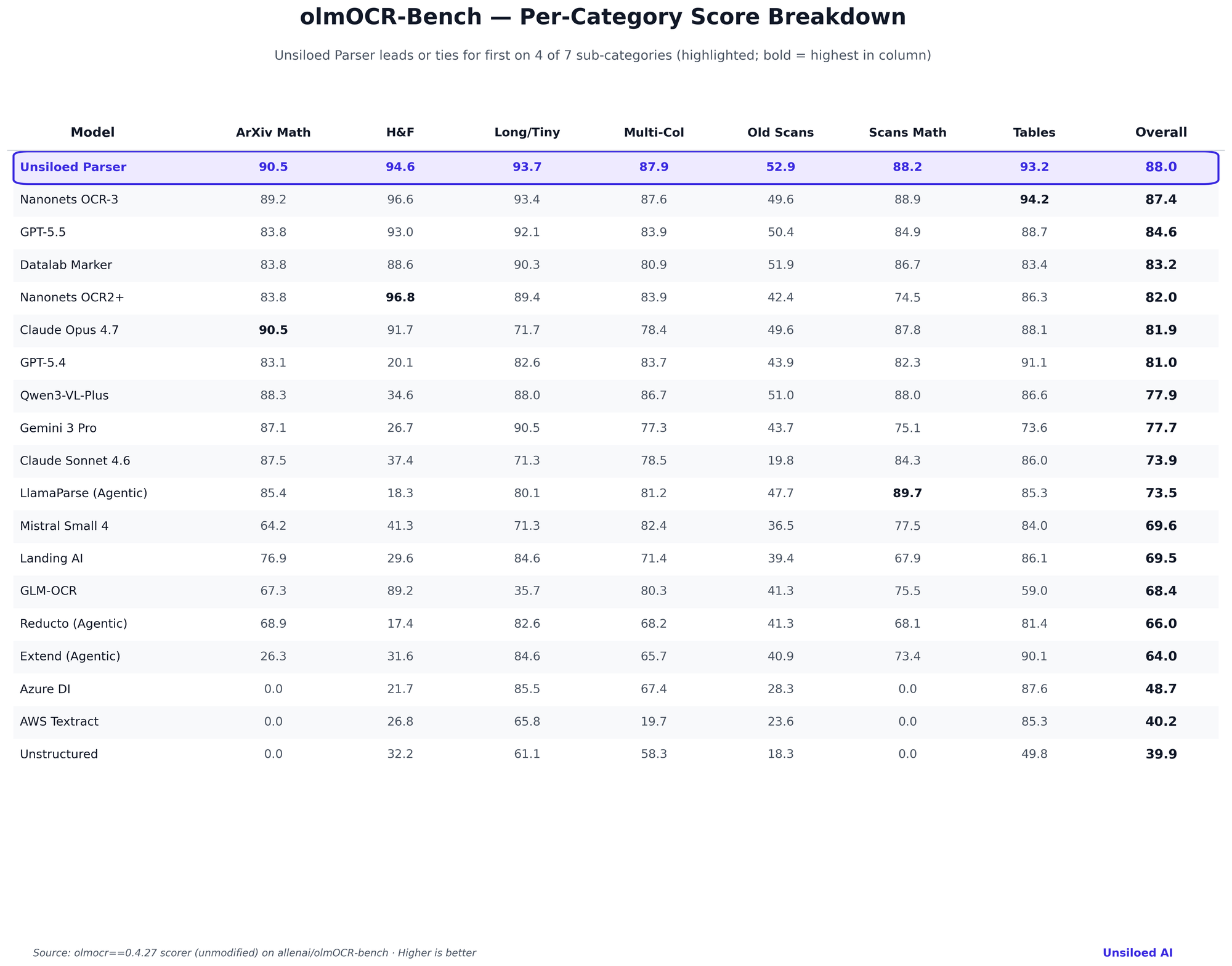
The full per-category table covers all 19 services. Unsiloed Parser leads or ties for first on 4 of 7 sub-categories: ArXiv Math (90.5), Long/Tiny (93.7), Multi-Col (87.9), and Old Scans (52.9). Nanonets OCR-3 wins Tables (94.2, with Unsiloed Parser second at 93.2), Nanonets OCR2+ wins H&F (96.8, ahead of Nanonets OCR-3's 96.6 and Unsiloed's 94.6), and LlamaParse Agentic wins Old Scans Math (89.7, ahead of Nanonets OCR-3's 88.9 and Unsiloed's 88.2).
olmOCR-Bench Results
| Rank | Service | Provider | Score |
|---|---|---|---|
| 1 | Unsiloed Parser | Unsiloed AI | 88.0 |
| 2 | Nanonets OCR-3 | Nanonets | 87.4 |
| 3 | GPT-5.5 | OpenAI | 84.6 |
| 4 | Datalab Marker | Datalab | 83.2 |
| 5 | Nanonets OCR2+ | Nanonets | 82.0 |
| 6 | Claude Opus 4.7 | Anthropic | 81.9 |
| 7 | GPT-5.4 | OpenAI | 81.0 |
| 8 | Qwen3-VL-Plus | Alibaba | 77.9 |
| 9 | Gemini 3 Pro | 77.7 | |
| 10 | Claude Sonnet 4.6 | Anthropic | 73.9 |
| 11 | LlamaParse (Agentic) | LlamaIndex | 73.5 |
| 12 | Mistral Small 4 | Mistral AI | 69.6 |
| 13 | Landing AI | Landing AI | 69.5 |
| 14 | GLM-OCR | Zhipu AI | 68.4 |
| 15 | Reducto (Agentic) | Reducto AI | 66.0 |
| 16 | Extend (Agentic) | Extend AI | 64.0 |
| 17 | Azure Document Intelligence | Microsoft | 48.7 |
| 18 | AWS Textract | Amazon | 40.2 |
| 19 | Unstructured | Unstructured AI | 39.9 |
Scores were evaluated against allenai/olmOCR-bench (1,403 PDFs / 8,413 tests) using the unmodified upstream olmocr==0.4.27 scorer, with per-service runner code open-sourced at github.com/Unsiloed-AI/unsiloed-olmocr-benchmark.
Why a Second Evaluation? Strict Pass-Rate vs. Semantic Correctness
olmOCR-Bench's headline metric is the deterministic, unit-test-driven pass-rate that we just reported. It's the right way to compare systems publicly: it's reproducible, it requires no second model in the loop, and the rules are fixed. 88.0 is our number on that metric, and it's the one that matters for ranking against the public leaderboard.
But once we had a leaderboard-leading number, we wanted to understand the remaining ~12% of "failures", what was actually wrong, and how much of it would matter to a downstream user reading the parsed document.
What the strict tests actually flag
olmOCR's strict tests are exact-string checks against a gold answer. By design, that strictness is what catches subtle errors but it also means any divergence from the reference string is recorded as a failure, even when the divergence is semantically harmless. In practice that includes things like:
- A ground truth of
"I am Name"(two spaces) vs. a prediction of"I am Name"(one space), scored as 0 even though no human reader would see a difference. - A math equation written with the literal Greek letter
ε(Epsilon) rather than\epsilon, the LaTeX form passes, the rendered glyph fails, despite producing identical output downstream. \frac{a}{b}vs.\dfrac{a}{b}vs.\tfrac{a}{b}(identical LaTeX rendering).\cdotvs.\timesfor multiplication, or\coloneqqvs.:=."0.70"vs."0. 70"inside a table cell.twenty-fivevs.twenty five(hyphenation), ASCII apostrophes vs. unicode curly quotes in transcribed handwriting.
These aren't OCR errors, they're string-level divergences from the gold reference that don't change what a downstream reader, search index, or LLM consuming the parsed document would see. But under strict pass/fail rules, every one of them counts as a failure and pushes a benchmark score down without telling you anything useful about model quality.
What LLM-as-a-Judge measures
For our own system, we re-ran every strict failure through an LLM-as-a-Judge (GPT-5.5, reasoning_effort=medium, seed=42) and asked: "the strict rule failed, is the OCR output actually wrong, or did the rule reject a semantically-equivalent rewrite?" Each verdict is minor (rescue → count as pass) or real (genuine OCR miss). Strict tests catch the surface-level divergence; the judge tells us whether that divergence changes what a reader of the document would understand.
This isn't a replacement for the strict score, it's a diagnostic on top of it that separates "rule said fail" from "the OCR was actually wrong."
The result
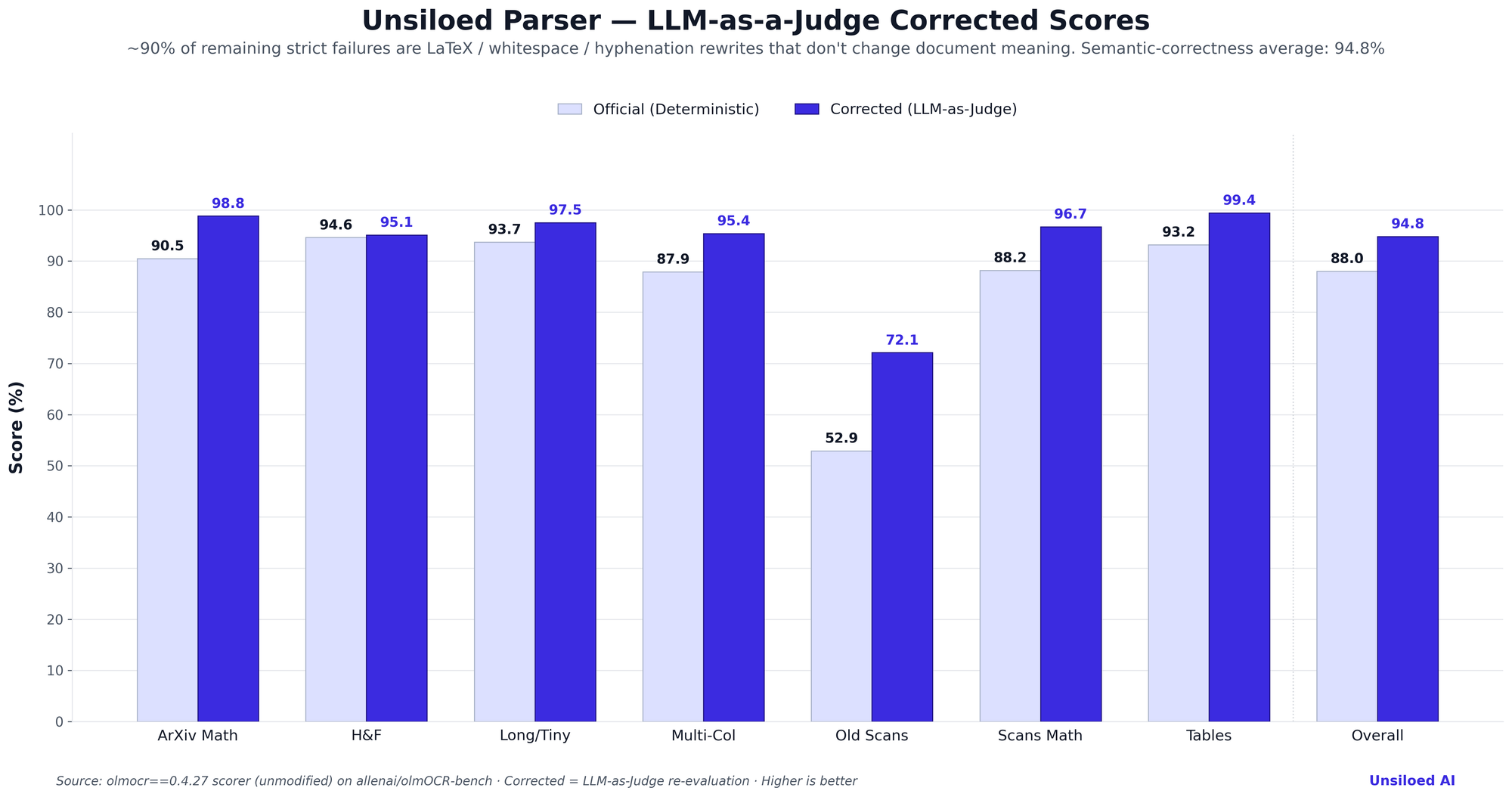
Re-aggregating with the rescues applied to the new configuration, Unsiloed Parser's semantic-correctness score is 94.8% (with-baseline 8-group macro), a +6.8-pp lift over the strict 88.0 baseline.
The breakdown by failure type (measured rescue rates on the current pipeline):
- Tables: 64 of 70 failures (91%) are string-level divergences with no semantic impact; the table-to-string parser, not the OCR, is the bottleneck.
- ArXiv Math: 243 of 277 failures (≈88%) are LaTeX-equivalent rewrites —
\fracvs\dfrac,\cdotvs\times, spacing/brace variants. - Old Scans: the hardest category sees the largest +19-point lift (52.9 → 72.1), where many "failures" are hyphenation/whitespace differences in handwriting transcriptions.
We didn't run the same LLM-as-Judge protocol against the other systems in this comparison, so we're not claiming a leaderboard rank on this metric. We share this number purely so readers can see what kind of failures remain at the top of the strict leaderboard, and judge for themselves whether those failures matter for their use case.
Limitations of current benchmarks
Looking past the leaderboard standings, our analysis surfaces fundamental problems with the way document-parsing systems are currently measured.
Today's OCR benchmarks score systems against rigid string-level rules. As we showed in the LLM-as-a-Judge analysis above, the majority of "failures" at the top of the leaderboard are not OCR errors at all, they're whitespace, hyphenation, and notation rewrites that don't change document meaning. (On the new Unsiloed run, ~65% of strict failures by raw count and ~61% averaged per category are LaTeX/whitespace/punctuation-equivalent rewrites; the macro-weighted rescue rate is ~57%.) There is currently no widely-adopted benchmark that scores OCR systems on semantic correctness against the ground truth.
Current OCR benchmarks were originally designed around academic-document workloads and may underrepresent emerging production document patterns. Existing benchmarks lean heavily on tables and equations content that was central to the academic-paper datasets these benchmarks were originally built from while underweighting the elements that dominate today's real-world document mix: charts and plots, multi-column layout, key-value pairs, forms, and structured fields. We're working on closing both gaps i.e. the semantic-aware evaluation and broader category coverage and plan to share more on this in the coming months.
Try It Yourself
If you want to skip the benchmark and just see Unsiloed Parser on your own documents, try the Unsiloed platform at unsiloed.ai/playground. Upload a document and compare extraction results across models side-by-side. No code required.
To reproduce the numbers or run your own vendor against the same harness, the full benchmarks repo, per-service runners, raw scorer logs, and JSON metrics is open-source at github.com/Unsiloed-AI/unsiloed-olmocr-benchmark.
Logos and trademarks are the property of their respective owners.Use does not imply endorsement
Data sourced using the unmodified olmocr==0.4.27 scorer (allenai/olmocr) on the allenai/olmOCR-bench dataset. Scores as of May 2026.