
Unsiloed AI vs Unstructured: Which is Better in June 2026?



The Unsiloed AI vs Unstructured comparison matters most when your documents stop being simple. Clean PDFs with single-column text work fine in most parsers. The real test comes with merged table cells, multi-column layouts, or scanned pages where OCR alone won't cut it. This breakdown covers how each tool handles the parsing cases that actually cause pipeline failures.
TLDR:
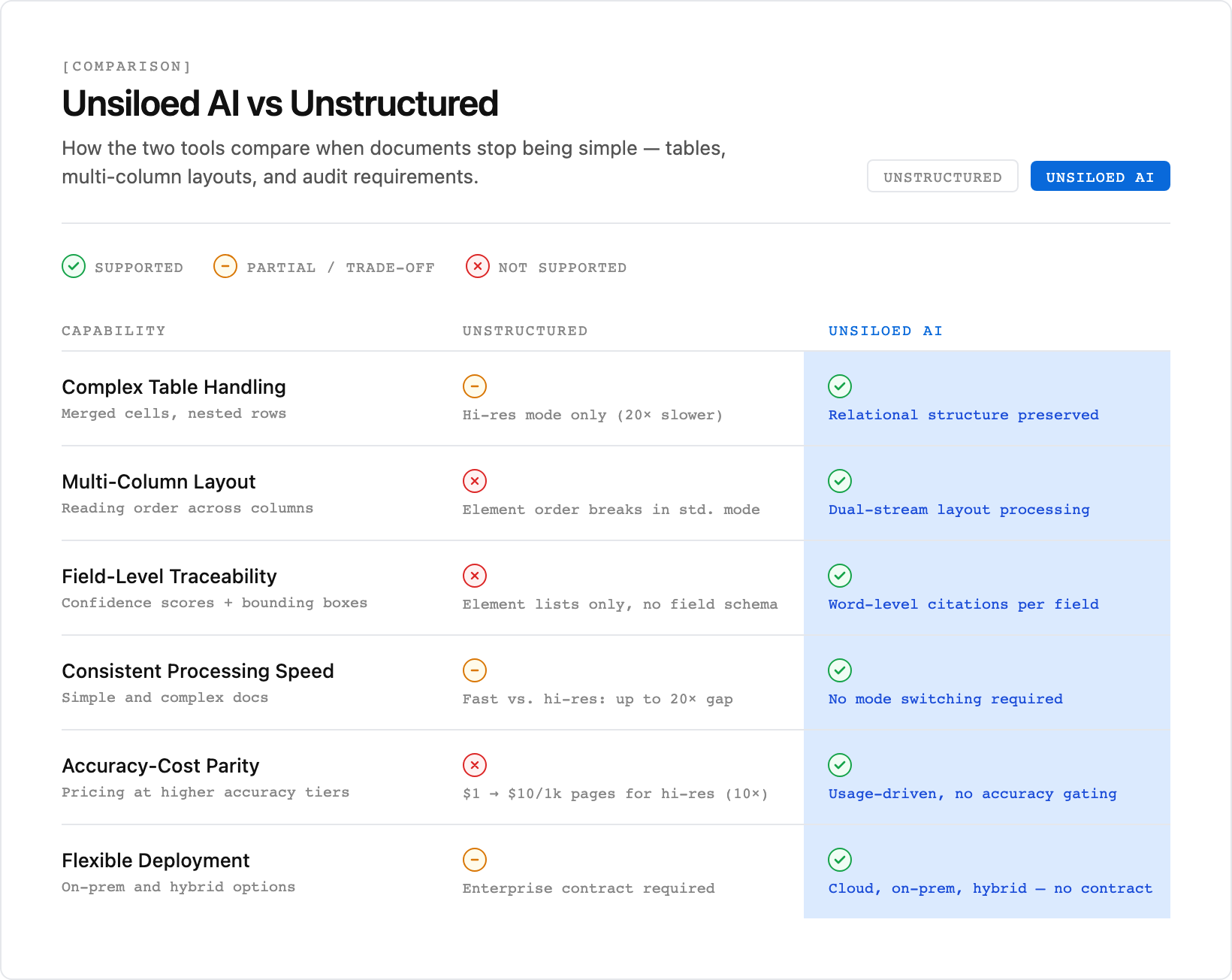
- Document parsing tools differ at the accuracy layer: element-based approaches break on complex tables and multi-column layouts, while vision-first architectures preserve relational structure.
- High-resolution processing modes can run up to 20x slower than fast modes, creating latency trade-offs when document complexity increases.
- Schema-based extraction returns structured JSON with confidence scores and bounding box coordinates, eliminating the need to build field-level logic on top of raw partitioned output.
- Pricing models split between flat per-page rates that apply the same premium to simple and complex documents alike, and usage-driven models that scale with actual consumption.
- Unsiloed AI processes semantic content and structural layout simultaneously, returning word-level citations that support audit requirements in finance, legal, and healthcare workflows.
What is the Alternative?
The competitor in this comparison is an AI-powered document processing and data extraction tool built around ingesting unstructured content at scale. Its core use case is preparing raw documents, PDFs, HTML, images, and other file types for downstream AI workflows by parsing and chunking that content into structured formats LLMs can consume.
The tool is widely used in retrieval-augmented generation (RAG) pipelines, where clean, well-chunked document data is a prerequisite before any querying or reasoning can happen. Teams typically plug it in as a preprocessing layer, feeding outputs into vector databases or LLM APIs.
Where It Fits in a Typical Stack
It sits at the ingestion layer of a data pipeline, not the reasoning or retrieval layer. That means you still need to build and maintain the surrounding infrastructure yourself, including orchestration, storage, embedding, and querying logic. For teams without that infrastructure already in place, the setup overhead can be heavy.
What is Unsiloed AI?
Unsiloed AI is a document processing API built for teams that need reliable, production-grade outputs from complex documents. At its core, it combines computer vision, OCR, and multimodal models to parse documents into deterministic Markdown and JSON that LLMs and AI agents can consume directly.
The main difference is at the parsing layer. Generic text extractors lose structure when documents get complex. Scanned forms, dense multi-column layouts, embedded charts, and nested tables all tend to break standard tools. Unsiloed AI is built to handle these failure cases, preserving the structural integrity that downstream AI workflows depend on.
What Unsiloed AI Handles Well
There are a few document types where this architecture stands out:
- Scanned or image-based PDFs where OCR alone produces garbled or out-of-order text
- Multi-column layouts that standard extractors flatten into unreadable single-column output
- Tables with merged cells or nested rows that lose their relational structure during extraction
- Documents with embedded charts or figures that need to be identified and positioned correctly in the output
Document Parsing Accuracy and Approach
The Unstructured parser uses an element-based approach, identifying components like titles, narrative text, tables, and list items. On clean, simple PDFs this works fine. The gaps surface once documents get complex.
Table handling is a well-documented weak point. Without advanced table detection or OCR alignment, structure breaks on complex layouts. Teams needing better accuracy can switch to high-resolution processing mode, but that trade-off is steep: it runs considerably slower than fast mode, and Unstructured's own documentation acknowledges it still struggles with deeply nested structures and multi-page spanning cells. Multi-column documents present another challenge, where element ordering frequently breaks down, producing output that reads nothing like the original source.
Table handling is a well-documented weak point. Without advanced table detection or OCR alignment, structure breaks on complex layouts. Teams needing better accuracy can switch to high-resolution processing mode, but that trade-off is steep: it runs up to 20 times slower than fast mode. Multi-column documents present another challenge, where element ordering frequently breaks down in both standard and hi-res modes, producing output that reads nothing like the original source.
How Unsiloed AI Handles Complex Documents
Unsiloed AI's dual-stream architecture handles these failure cases by processing semantic content and structural layout simultaneously, not as separate passes.
- Reading order stays intact across multi-column and irregular layouts.
- Tables retain their relational structure, including nested and merged cells.
- Every extracted element comes with confidence scores and word-level bounding boxes, giving your pipeline full visibility into output quality.
- Charts and figures embedded in documents are identified and positioned correctly in the output.
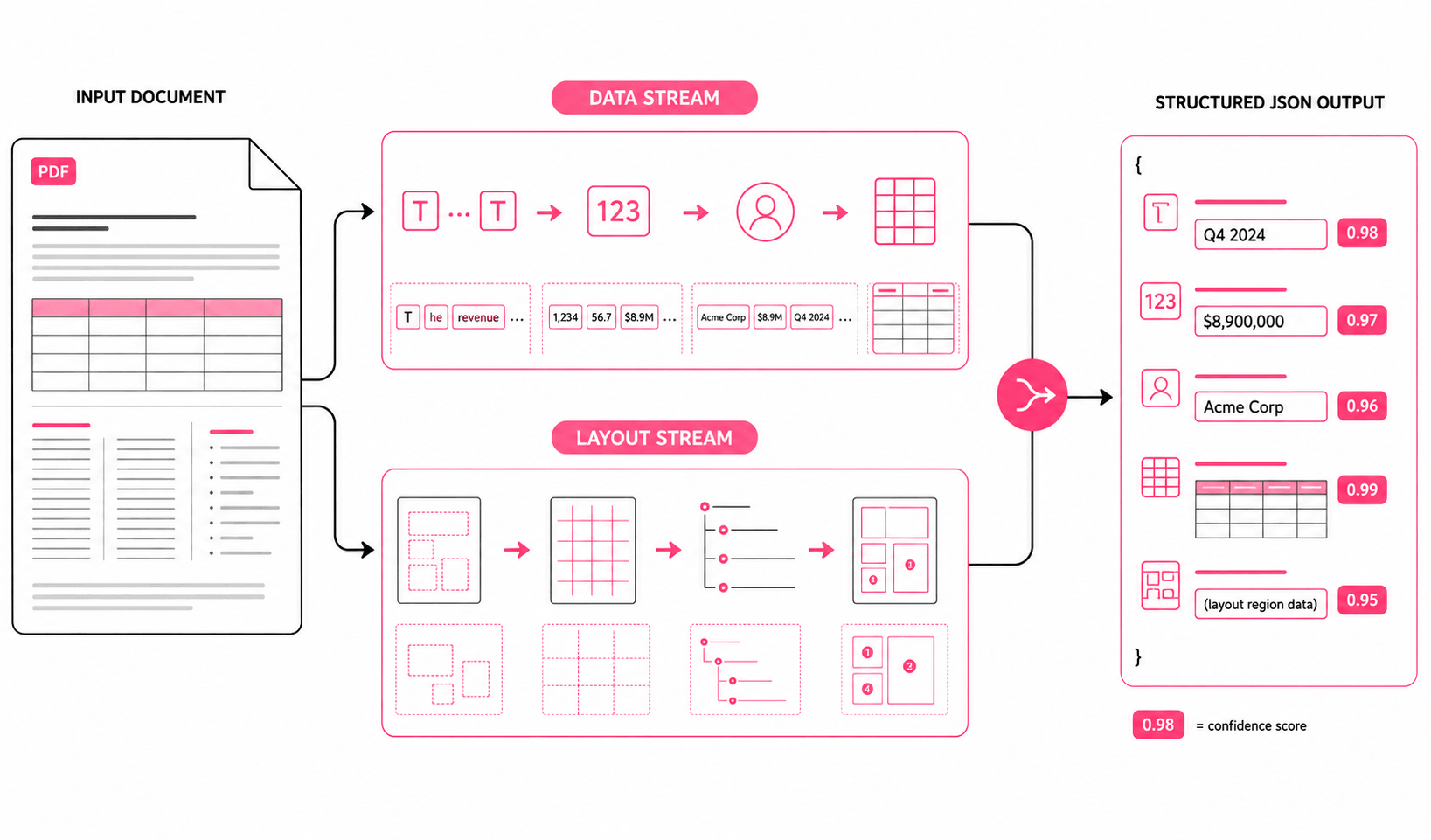
Unsiloed AI's dual-stream architecture processes semantic content and structural layout as parallel streams, preserving reading order and table structure that element-based parsers lose.
Schema-Based Extraction and Field-Level Traceability
Unsiloed AI's /v2/extract endpoint takes a fundamentally different approach. You pass a JSON schema describing the fields you need, submit a document, and get back structured JSON where each field carries a confidence score, page reference, and bounding box coordinates tied to its exact source location. Every extraction is traceable at the word level, beyond the document level.
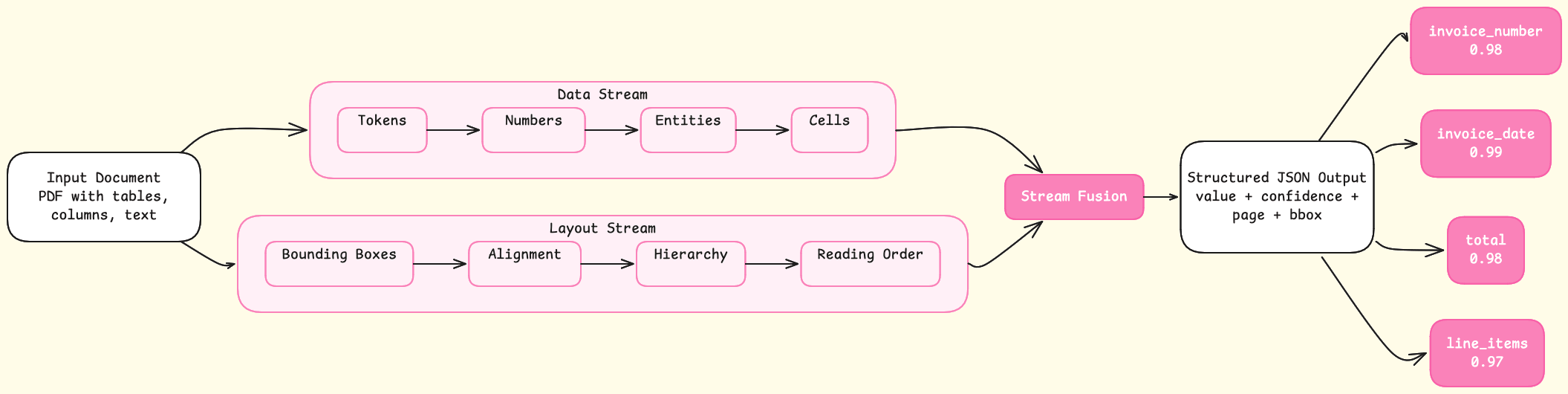
The data and layout streams converge at stream fusion, producing structured JSON where every field — invoice number, date, total, line items — carries its own confidence score.
A single parsed segment looks like this:
{
"segment_type": "SectionHeader",
"content": "Q1 2024 Sales Report",
"confidence": 0.94,
"page_number": 1,
"bbox": { "left": 427.6, "top": 67.8, "width": 344.7, "height": 36.5 },
"ocr": [
{ "text": "Q1", "confidence": 0.9999, "bbox": { "left": 5.4, "top": 4.1, "width": 35.6, "height": 22.7 } },
{ "text": "2024", "confidence": 0.9999, "bbox": { "left": 56.4, "top": 4.1, "width": 69.4, "height": 22.7 } }
]
}The other tool stops at the partitioning layer. You get element lists tagged by type, but no native mechanism to define specific fields and receive validated structured JSON in return. Extracting invoice totals, contract dates, or line items means building that logic yourself on top of raw output.
{
"type": "NarrativeText",
"element_id": "5ef1d1117721f0472c1ad825991d7d37",
"text": "The Unstructured documentation covers the following services:",
"metadata": {
"page_number": 1,
"languages": ["eng"]
}
}Why Field-Level Traceability Matters
- Confidence scores let you flag low-certainty extractions for human review before they flow into downstream systems.
- Bounding box coordinates tie each extracted value back to its exact position in the source document, making audits and compliance checks straightforward.
- Schema-driven output means the response shape is predictable, which keeps your integration code simple and brittle-free.
Processing Speed and Scalability
Unsiloed AI is built to handle high-throughput document processing without the latency trade-offs you get with batch-based architectures. Where the competitor targets batch and near-real-time workloads, that model introduces friction when pipelines require predictable, consistent throughput at low latency.
At the enterprise tier, the competitor reports support for up to 300 concurrent jobs and 15 million pages per hour per data plane. That raw scale exists, but it comes at a price point structured around that tier.
What to Consider for Your Workload
When assessing processing speed and scalability, the right questions to ask are:
- Whether your pipeline needs sub-second response times or can tolerate batch-style processing windows
- How predictably throughput needs to hold under variable load, beyond peak conditions
- What the cost curve looks like as you scale concurrent jobs, since enterprise tier pricing can grow faster than usage
For teams running real-time extraction or serving live user-facing workflows, latency consistency matters as much as peak throughput capacity.
Deployment and Integration Options
Both tools take different approaches to deployment that reflect their underlying design philosophies.
The competitor is built around a cloud-native, API-first architecture. You can spin up document parsing pipelines quickly, but customization depth is limited unless you're working within their managed cloud environment. On-premise deployment exists but requires enterprise contracts, and self-hosted options come with meaningful setup overhead.
Unsiloed AI offers flexible deployment across cloud, on-premise, and hybrid configurations without locking you into a specific infrastructure model. You can connect to your existing data sources through prebuilt connectors or build custom integrations via REST APIs. The system is designed to work within your security perimeter, which matters for teams handling sensitive or regulated data.
Connector Coverage and API Access
Where the two products differ most for engineering teams is connector depth and control:
- Unsiloed AI ships with connectors for databases, cloud storage, SaaS tools, and internal knowledge bases, so you're not rebuilding ingestion logic from scratch each time you add a new source.
- The competitor focuses its integration story on document input formats rather than source systems, which means more preprocessing work falls on your team.
- REST API access in Unsiloed AI gives developers direct control over pipeline configuration, chunking behavior, and retrieval parameters without requiring workarounds.
For teams that need to move fast without sacrificing control over how data flows through the system, the integration architecture is where Unsiloed AI tends to pull ahead.
Pricing and Cost Structure
Unstructured offers a free tier covering 15,000 pages with no expiration, then moves to pay-as-you-go pricing at a flat $0.03 per page ($30 per 1,000 pages) with no minimums or commitments. That flat rate applies the same premium whether the document is a clean single-column PDF or a complex scanned table, and it does not scale down as volume grows, which puts teams processing dense or high-volume document sets in a difficult position.
Unsiloed AI runs on a credit-based, usage-driven model. Enterprise plans cover high-volume workloads with dedicated infrastructure, and on-premise deployments are priced separately based on configuration requirements. Specific pricing is available by reaching out to support@unsiloed.ai The underlying structure is built to scale with actual usage rather than apply a flat per-page premium regardless of document complexity.
Feature | Unsiloed AI | Unstructured |
|---|---|---|
Parsing Architecture | Dual-stream vision-first architecture that processes semantic content and structural layout simultaneously | Element-based approach identifying components like titles, narrative text, tables, and list items |
Complex Table Handling | Preserves relational structure including nested and merged cells with word-level bounding boxes | Basic table detection; relational structure collapses on merge-heavy layouts without high-resolution mode |
Multi-Column Document Processing | Maintains reading order across irregular layouts without mode switching | Element ordering frequently breaks down on multi-column documents in standard mode |
Output Format and Traceability | Schema-based extraction returning structured JSON with confidence scores, page references, and bounding box coordinates for every field | Partitioned element lists tagged by type; no native field-level extraction or confidence scoring |
Processing Speed Trade-offs | Consistent latency across simple and complex documents without mode switching | Fast mode for simple docs; high-resolution mode runs up to 20x slower for complex documents |
Deployment Options | Flexible cloud, on-premise, and hybrid configurations without enterprise contracts for self-hosting | Cloud-native API-first architecture; on-premise requires enterprise contracts |
Pricing Model | Credit-based usage-driven model that scales with actual usage without gating accuracy behind premium tiers | $1 per 1,000 pages fast mode, $10 per 1,000 pages hi-res mode (10x cost jump for accuracy) |
Why Unsiloed AI is the Better Choice
The right choice depends on what your pipeline actually needs.
If you're building an early prototype, working primarily with clean PDFs, or already invested in an open-source ecosystem with LangChain and vector database tooling, the competitor is a reasonable starting point. Its broad format support and community integrations cover a lot of standard preprocessing scenarios without much setup friction.
But if your documents are complex, your extractions need to be auditable, or your industry carries real cost for parsing errors, Unsiloed AI is the stronger fit. Finance, legal, and healthcare workflows have very little tolerance for garbled tables or misread figures. Our vision-first architecture was built for those conditions, and the deterministic outputs with word-level citations give your team the traceability to catch problems before they propagate downstream.
For teams building document-driven AI agents or production RAG pipelines, accuracy at the ingestion layer is what everything else depends on.
If you're ready to see how we handle your actual documents, reach out at hello@unsiloed-ai.com or try the demo at unsiloed.ai/demo.
Final Thoughts on Document Processing Accuracy
Parsing quality at the ingestion layer sets the ceiling for everything your AI pipeline can do. Unsiloed AI gives you the structure-preserving extraction and field-level confidence scores that production systems depend on. Your documents are the best test, so try our demo with the files that actually break your current tooling.
FAQ
How should I decide between these two document processing tools?
Start with your document types and accuracy requirements. If you're working with clean, simple PDFs in an early-stage prototype, a general-purpose parser will likely suffice. If your documents contain complex tables, multi-column layouts, or scanned content where extraction errors carry real business cost, Unsiloed AI's vision-first architecture is built for those conditions.
What's the main difference in how tables are extracted?
General element-based parsers identify table components but often lose relational structure when cells are merged or nested. Unsiloed AI processes tables through a dual-stream architecture that preserves row-column relationships while providing word-level bounding boxes and confidence scores for every extracted cell, making the output auditable and production-ready.
Who is each tool best suited for?
General document parsers work well for teams with existing LangChain infrastructure processing straightforward PDFs at high volume. Unsiloed AI is built for finance, legal, and healthcare teams where parsing accuracy directly impacts compliance, audit trails, or downstream automation reliability—particularly when working with scanned forms, financial statements, or contracts.
Can I deploy on-premise if my data can't leave our environment?
Unsiloed AI supports on-premise, air-gapped, and hybrid deployment configurations without requiring enterprise contracts for basic self-hosting. The other tool offers on-premise deployment but structures it around enterprise agreements, which can extend procurement timelines if you need to keep data within your security perimeter.
What happens when I need high-resolution processing for complex documents?
With typical batch-oriented architectures, switching to high-resolution modes can slow processing by up to 20x and increase per-page costs by 10x. Unsiloed AI handles complex documents without mode switching—the same vision-based pipeline processes both simple and complex layouts while maintaining consistent latency and cost structure.
Continue reading

PDF Parsing in Node.js: A Complete Technical Guide (June 2026)

Unsiloed AI vs Pulse: Which is Better in June 2026?



