
Unsiloed AI vs Pulse: Which is Better in June 2026?


If you're comparing Unsiloed AI and Pulse, you're looking at two document extraction platforms that solve the same core problem: turning complex, unstructured documents into structured data that LLMs, AI agents, and RAG pipelines can consume reliably. Both use vision-first parsing to preserve layout and table structure, both return confidence-scored output, and both support regulated-industry deployment. The decision comes down to how each one exposes that capability: the granularity of its output and traceability, the shape of its API surface, and how its accuracy holds up on the document types your workflow actually depends on.
TLDR:
- Both Unsiloed AI and Pulse convert unstructured documents like PDFs, scanned files, and financial filings into structured JSON for AI pipelines, using vision-first parsing rather than plain-text OCR.
- Unsiloed returns every field with a confidence score, bounding box, and word-level citation by default, giving downstream systems token-level provenance.
- Unsiloed exposes parsing, extraction, classification, and splitting as four separate API endpoints, so each step in a pipeline is its own composable call.
- Both support cloud, on-premise, and air-gapped deployment with SOC 2 and HIPAA, so deployment rarely decides the comparison. The deciding factors are usually output granularity and API design.
What is Pulse?
Pulse is a document intelligence platform that converts unstructured documents into structured, machine-readable data. It combines optical character recognition (OCR), layout analysis, and vision-language models to read PDFs, scanned forms, handwriting, tables, and charts, then returns structured output for downstream systems.
The product targets enterprises in regulated sectors such as finance, insurance, healthcare, legal, real estate, and supply chain, where documents are dense, high-volume, and compliance-sensitive. Its pipeline detects structural elements like tables, charts, and stamps before extraction, applies a reasoning layer when layout cues are ambiguous, and validates field types and units against a schema before returning output.
Pulse and Unsiloed AI sit in the same category: both are infrastructure for extracting structured data from unstructured documents, not end-user applications. That overlap is what makes this comparison a question of architecture and output design rather than one of category fit.
What is Unsiloed AI?
Unsiloed AI is the unstructured data interface for LLMs and AI agents. The system combines computer vision, OCR, and multimodal models to convert complex documents into structured, machine-readable representations. The output feeds directly into RAG pipelines, AI agents, and document-driven automations.
The product is built around four APIs:
- Parsing converts documents into structured, hierarchical chunks while preserving reading order, tables, charts, and visual hierarchy.
- Extraction pulls specific fields from documents using custom JSON schemas, returning each value with a confidence score, bounding box, and word-level citation back to the source.
- Classification routes documents by type using both visual and semantic signals.
- Splitting breaks mixed or merged files into logical sections for downstream processing.
Support spans more than 20 file formats, including PDFs, DOCX, PowerPoint, Excel, and scanned images. Engineers build on top of Unsiloed; it sits between raw document storage and whatever AI system runs downstream.
How Unsiloed AI and Pulse Compare
Because both tools target the same problem, the useful comparison is across the dimensions where their approaches diverge: parsing architecture, output and traceability, API surface, and how each reports accuracy.
Capability | Unsiloed AI | Pulse |
|---|---|---|
Parsing approach | Vision-first dual-stream parsing of semantic content and layout in a single pass | Vision-language pipeline with structural detection and an adaptive reasoning layer |
Output and traceability | Per-field confidence score (0–1), bounding box, and word-level citation in every response by default | Confidence-aware output with schema validation of field types and units |
Document classification endpoint | Yes, routes documents by type using visual and semantic signals | Not a documented endpoint (parsing, extraction, splitting, and schema only) |
Structured JSON via custom schema | Yes | Yes |
Complex tables, multi-column, scanned and handwritten input | Yes | Yes |
Accuracy benchmark | #1 on olmOCR-Bench (88.0), a public, independently reproducible benchmark | Reports accuracy on its own internal PulseBench suite |
Cloud, on-premise, and air-gapped deployment | Yes | Yes |
SOC 2 and HIPAA support | Yes | Yes |
No training on customer data | Yes | Yes |
Parsing Architecture and Document Coverage
Both tools handle a wide range of formats, including PDFs, Office files, images, and scanned documents, with vision-first parsing that preserves layout, reading order, and table structure rather than flattening everything into a single text stream. For the single-column documents most pipelines start with, either tool performs well. The differences emerge on structure-heavy content: dense financial filings, multi-column layouts, merged and nested table cells, and scanned pages.
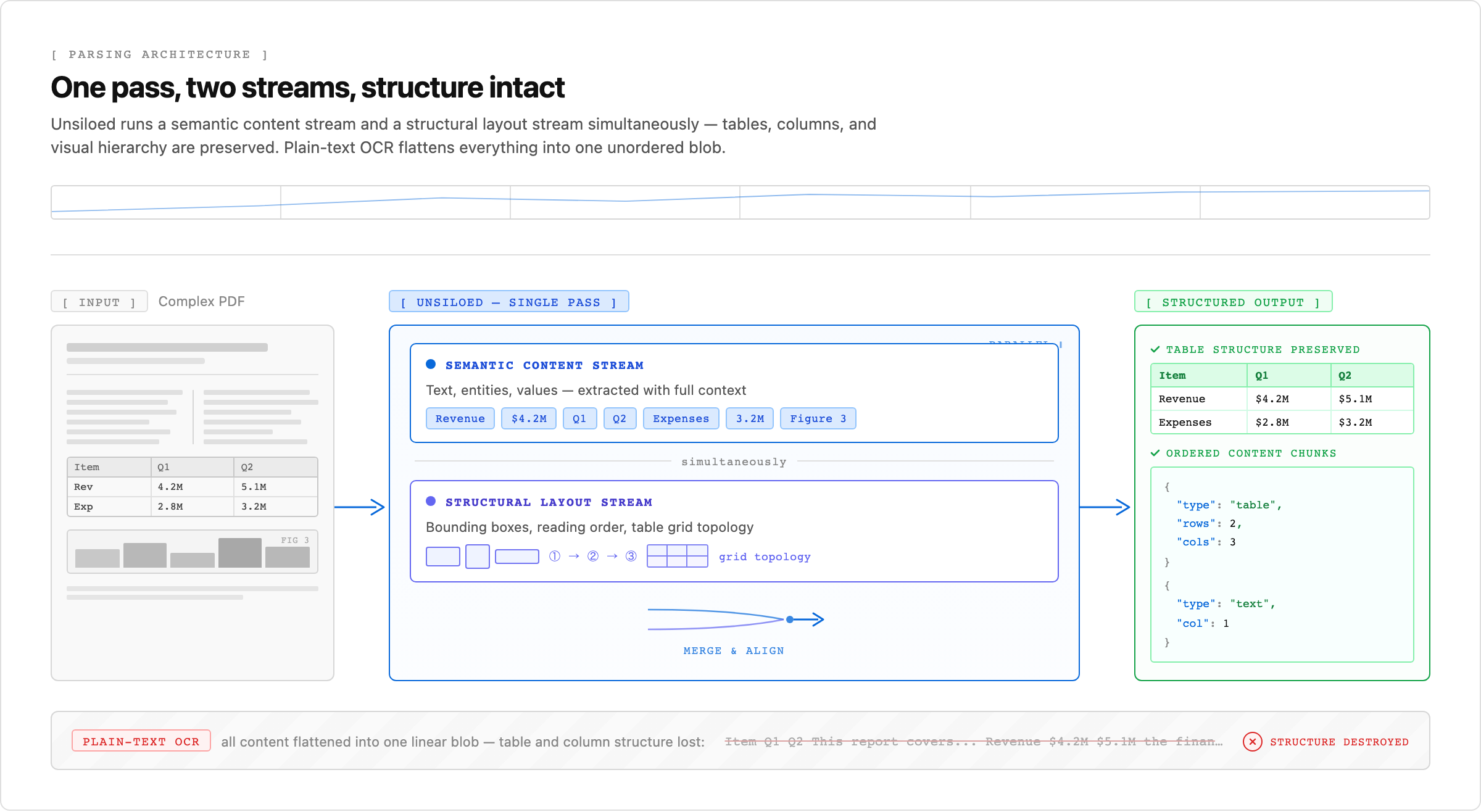
Unsiloed runs semantic content and structural layout as parallel streams in one pass, so tables and reading order survive extraction. Plain-text OCR collapses the same page into a single linear blob.
Unsiloed uses a dual-stream architecture that processes semantic content and structural layout simultaneously, so tables, headers, and multi-column text keep their relationships in the output. It reports a top score of 88.0 on olmOCR-Bench, a public OCR benchmark anyone can run, which gives an external, reproducible reference point for accuracy on complex pages rather than a vendor-defined one. Pulse takes a comparable vision-first approach, detecting structural elements before extraction and applying a reasoning layer when layout cues are ambiguous, and publishes accuracy results on its own internal PulseBench suite.
For RAG pipelines where retrieval accuracy depends on clean, structure-aware chunks, the parsing layer matters more than most teams expect before they hit production. Effective RAG pipeline architecture requires preserving document structure during ingestion to maintain retrieval quality downstream. Data quality in RAG ingestion depends on preprocessing that removes noise while maintaining the semantic relationships encoded in document layout.
Output and Traceability
Traceability is a production requirement in regulated industries, not a nice-to-have. When an extraction returns an incorrect value, teams need to know where it came from and how confident the system was at the time of extraction.
Both tools return confidence-aware output. Unsiloed AI goes further on granularity: every extracted field comes back with a confidence score between 0 and 1, a bounding box, and a word-level citation back to the source page, with token-level bounding boxes in the OCR array. That provenance is built into every API response by default rather than reconstructed downstream. Teams running straight-through automation can set thresholds directly off the per-field scores, for example routing fields above 0.9 to automation and fields between 0.7 and 0.9 to human review.
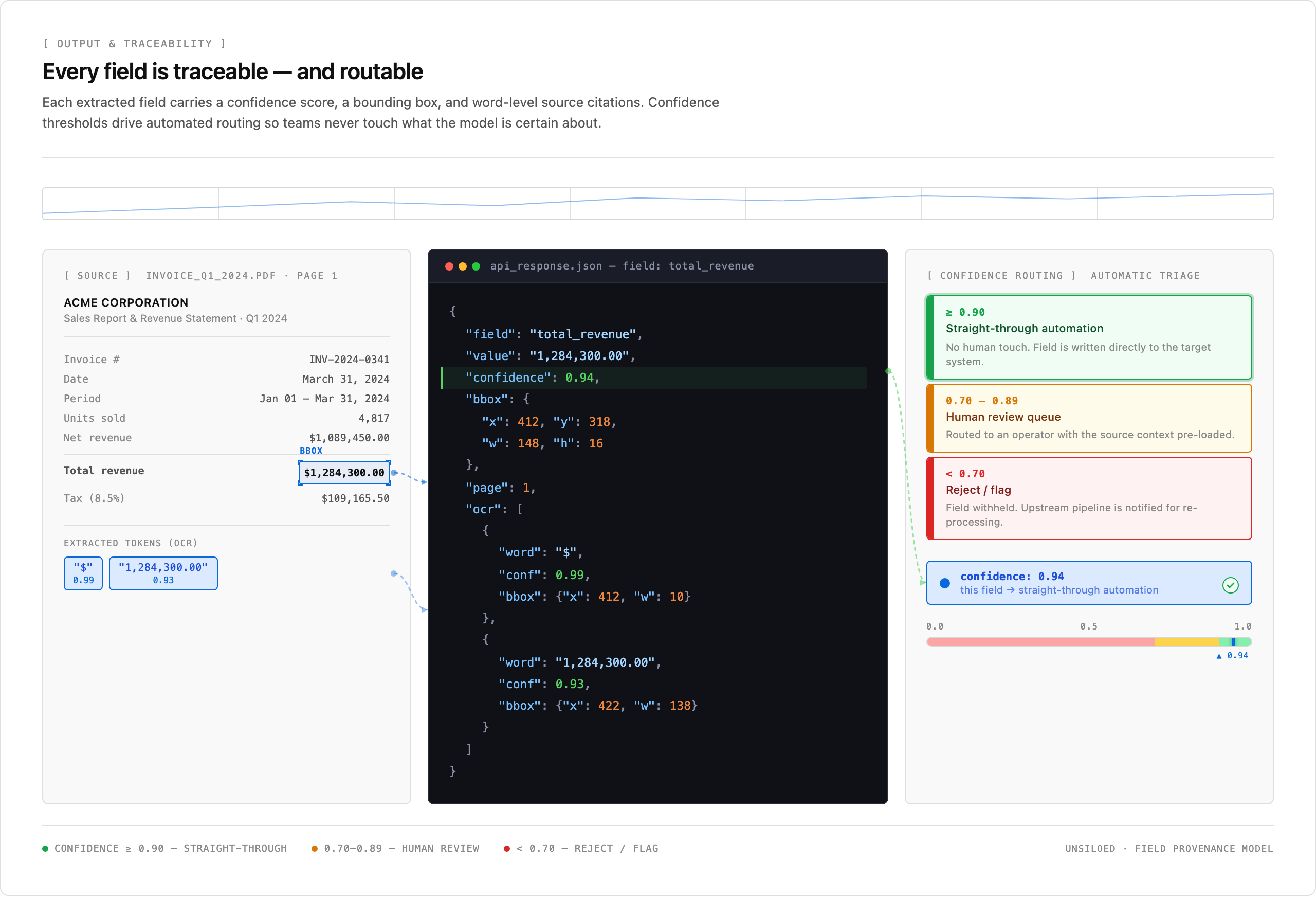
Every field returns a confidence score, bounding box, and word-level citation. The confidence score drives automatic routing: 0.90 and above for straight-through automation, 0.70 to 0.89 for human review, below 0.70 for reject or flag.
Pulse provides confidence-aware output and validates extracted fields against schema-defined types and units before returning them, which catches structural errors early. Where Unsiloed differentiates is the word-level citation back to source, which gives downstream systems a token-level audit trail without additional tooling.
Where Each Tool Fits
- Unsiloed AI suits engineering teams that want composable parsing, extraction, classification, and splitting primitives, with per-field confidence scores and word-level citations for audit and compliance workflows.
- Pulse suits teams that want a managed extraction platform proven at very high page volumes, with structural detection and schema validation built into the pipeline.
Both serve finance, legal, healthcare, and similar regulated domains, so the choice is less about industry fit and more about how much output granularity and API composability your pipeline needs.
Deployment and Enterprise Security
Deployment model is often where enterprise procurement decisions get made, and here the two tools are closely matched. Both run as managed cloud services, and both support on-premise and air-gapped or virtual private cloud (VPC) deployment for organizations that cannot route sensitive documents through third-party infrastructure. Both also support the SOC 2 and HIPAA requirements that financial institutions, healthcare organizations, and legal teams operate under.
For teams in finance, healthcare, or government, that means neither tool is disqualified on deployment grounds. The decision returns to parsing fidelity, output traceability, and API design rather than infrastructure or compliance posture.
Why Unsiloed AI is the Better Choice for Production Document Processing
Unsiloed AI and Pulse are both capable document extraction platforms, so the case for Unsiloed rests on specifics rather than category:
- Output granularity: every field returns a confidence score, a bounding box, and a word-level citation by default, giving downstream systems a token-level evidence trail without extra tooling.
- Built-in document classification: a dedicated endpoint routes documents by type using visual and semantic signals, so mixed-format batches can be triaged in the same pipeline that parses, splits, and extracts them. Pulse's documented API covers parsing, extraction, splitting, and schema, but not classification.
- Benchmark transparency: Unsiloed reports a leading score on the public olmOCR-Bench, which is easier to validate against than a vendor's internal suite.
- Deployment flexibility: cloud, on-premise, and air-gapped options meet the same regulated-industry bar Pulse does, so adopting Unsiloed does not trade away security posture.
Teams that want a managed, high-throughput extraction service will find Pulse fits their workflow. Teams that want fine-grained, auditable output and composable primitives to build production RAG and document-automation pipelines will get more control from Unsiloed's architecture.
Final Thoughts on Unsiloed AI and Pulse for Document Processing
Pulse and Unsiloed AI solve the same problem: converting complex documents into structured data that downstream systems can consume. They differ in output granularity, API composability, and how they report accuracy. If word-level traceability and composable parsing, extraction, classification, and splitting are what your pipeline needs, book a demo to see how Unsiloed's architecture handles the documents that break other tools.
FAQ
How should I decide between Unsiloed AI and Pulse for my workflow?
Both tools extract structured data from complex documents like contracts, financial filings, and medical records for RAG systems and AI agents, so the decision is about how that output is shaped rather than which problem it solves. Choose Unsiloed AI if you need word-level citations, per-field confidence scores, and composable parsing, extraction, classification, and splitting APIs. Choose Pulse if you want a managed extraction platform tuned for very high page volumes.
What makes Unsiloed AI's approach different from Pulse's document handling?
Both use vision-first architectures that preserve layout, reading order, and table structure. Unsiloed AI differentiates on output granularity and API design: it returns every extracted field with a confidence score, bounding box, and word-level citation back to the source by default, and exposes parsing, extraction, classification, and splitting as four discrete API operations.
Which teams should choose Unsiloed AI over Pulse?
AI/ML engineering teams building RAG pipelines, backend engineers integrating document processing into production systems, and organizations in finance, legal, healthcare, or mortgage that need token-level traceability and composable extraction primitives should choose Unsiloed AI. Teams that mainly need a managed, high-throughput extraction service may find Pulse a better fit.
Can I deploy Unsiloed AI in an on-premise or air-gapped environment?
Yes. Unsiloed AI supports cloud deployment, on-premise installations, and air-gapped environments, which makes it viable for organizations with strict data residency requirements under HIPAA, SOC 2, or internal governance policies. Pulse also offers cloud, VPC, and on-premise deployment, so both tools can run inside a controlled security perimeter.
What happens if I need to process scanned documents or files with irregular layouts?
Both tools handle scanned documents, multi-column layouts, and structure-heavy content with vision models that detect spatial relationships and preserve them in the output. Unsiloed AI returns that output with per-field confidence scores and word-level citations, so low-certainty extractions from difficult source pages are visible before they reach downstream systems.


