
Unsiloed AI vs LlamaIndex: Which RAG Platform Should You Pick in June 2026?


If you're comparing Unsiloed AI and LlamaIndex for document-heavy AI work, the question that should drive the decision is whether you can trust every value your pipeline pulls out of a document. Unsiloed AI returns each extracted value with a confidence score, and can cite it back to its exact location in the source, so an agent or a compliance reviewer can verify it instead of taking it on faith. Both products are managed document-AI platforms, but only one is built so that every value it returns is checkable. For regulated, high-stakes documents, that is what decides how much of the output you can act on without a human re-reading the page.
TLDR:
- Unsiloed AI and LlamaIndex (through its managed LlamaCloud platform) are both managed platforms that parse, extract, classify, split, and retrieve. This is a platform comparison, not managed versus build-it-yourself.
- Unsiloed returns a confidence score on every extracted field by default, plus bounding-box citations on request, so each value is traceable back to its exact position in the source.
- Unsiloed ranks #1 on the public olmOCR-Bench (88.0) and attaches a confidence score and bounding box to every value it parses, not only to final extracted fields.
- Choose Unsiloed when extraction has to be auditable and every value verifiable. LlamaIndex is mainly worth a look if you are already standardized on its open-source stack.
What is LlamaIndex?
LlamaIndex began as an open-source data framework for connecting LLMs to external data: document loaders, chunking, query engines, and vector-store integrations for building RAG pipelines. That library is still widely used, and its document-processing features now run on LlamaCloud, LlamaIndex's managed platform.
LlamaCloud is a managed offering that covers parsing, schema-based extraction, classification, splitting, and indexing for retrieval, all through a single API. So this is not a "managed API versus assemble it yourself" comparison: both Unsiloed and LlamaCloud are managed platforms. The question that matters is what each one returns once a document reaches production, and that is where they part ways.
What is Unsiloed AI?
Unsiloed AI is agentic OCR for AI pipelines that need to trust the page. It turns PDFs, scans, slides, spreadsheets, Office files, and HTML into Markdown and structured JSON, with a confidence score and a bounding box on every value. The API sits between your raw files and your retrieval, extraction, or automation pipeline.
The product covers four document operations, plus a workflow layer that chunks, embeds, and stores documents in a hosted vector index for retrieval:
- Parsing converts documents into hierarchical Markdown chunks while preserving reading order, tables, charts, and headers as first-class segments.
- Extraction pulls fields from a custom JSON schema and returns each value with a confidence score, plus optional bounding-box citations that locate it in the source.
- Classification routes documents by type using visual and semantic signals.
- Splitting separates merged or scanned batches into individual documents.
What sets Unsiloed apart is verifiability as a default. Every parsed segment and every extracted field comes back with a confidence score between 0 and 1, and you can return bounding-box citations that tie each value to its exact position in the source document. That makes it a fit for finance, legal, healthcare, and other domains where an extracted value has to be checkable, not just plausible.
How Unsiloed AI and LlamaIndex Compare
Both platforms cover the same core operations, so the comparison below focuses on what each one returns and how verifiable that output is, rather than on which features exist at all.
Capability | Unsiloed AI | LlamaIndex (LlamaCloud) |
|---|---|---|
Per-field confidence and source citations on extracted fields | Confidence by default, bounding-box citations on request | Not currently documented |
Confidence score and bounding box on every parsed value | Yes | Bounding boxes via layout extraction |
Public OCR benchmark result | #1 on olmOCR-Bench (88.0) | Publishes its own benchmarks |
Cloud, on-premise, and air-gapped deployment | Yes | Self-hosted on Enterprise plans only |
Schema-driven structured extraction | Yes | Yes (LlamaExtract) |
Managed parse, classify, split, and retrieval pipeline | Yes | Yes |
Parsing Accuracy and Structure
Accurate parsing is where many RAG pipelines quietly fail. PDFs with complex layouts, scanned images, multi-column tables, and nested headers all introduce extraction errors that compound downstream in retrieval and generation. Enterprise teams face document processing bottlenecks when scaling generative AI applications beyond prototypes.
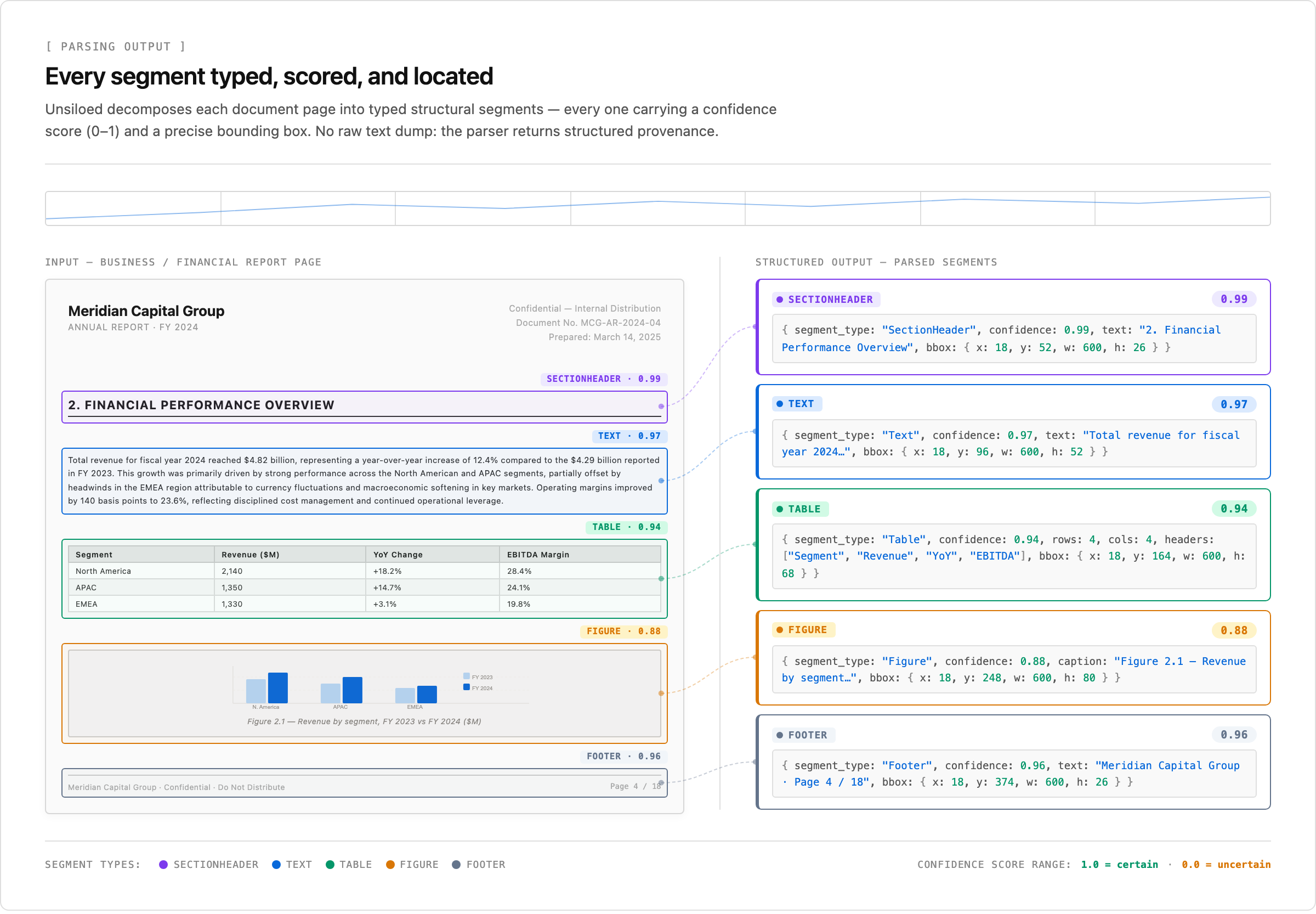
Unsiloed returns each page as typed segments, and every segment carries a confidence score and a bounding box, so low-certainty regions are visible before they reach retrieval.
Both tools use vision and layout models, so document structure survives the parse. Unsiloed parses PDFs, Office files, images, and HTML, keeping tables as structured data and preserving reading order on multi-column and irregular layouts. It also publishes a leading score of 88.0 on olmOCR-Bench, a public benchmark anyone can run and reproduce, while LlamaParse reports against its own internal benchmarks.
The difference shows up in what each parsed value carries. Unsiloed attaches a confidence score and a bounding box to every segment it returns, so a pipeline can flag low-certainty regions before they reach retrieval. That per-value signal is the foundation for the extraction output covered next.
Verifiable Extraction Output
Pulling structured data out of unstructured documents is where pipelines handling money, contracts, or patient records carry the most risk. A plausible-looking value that is silently wrong is worse than an obvious failure, because nothing downstream catches it.
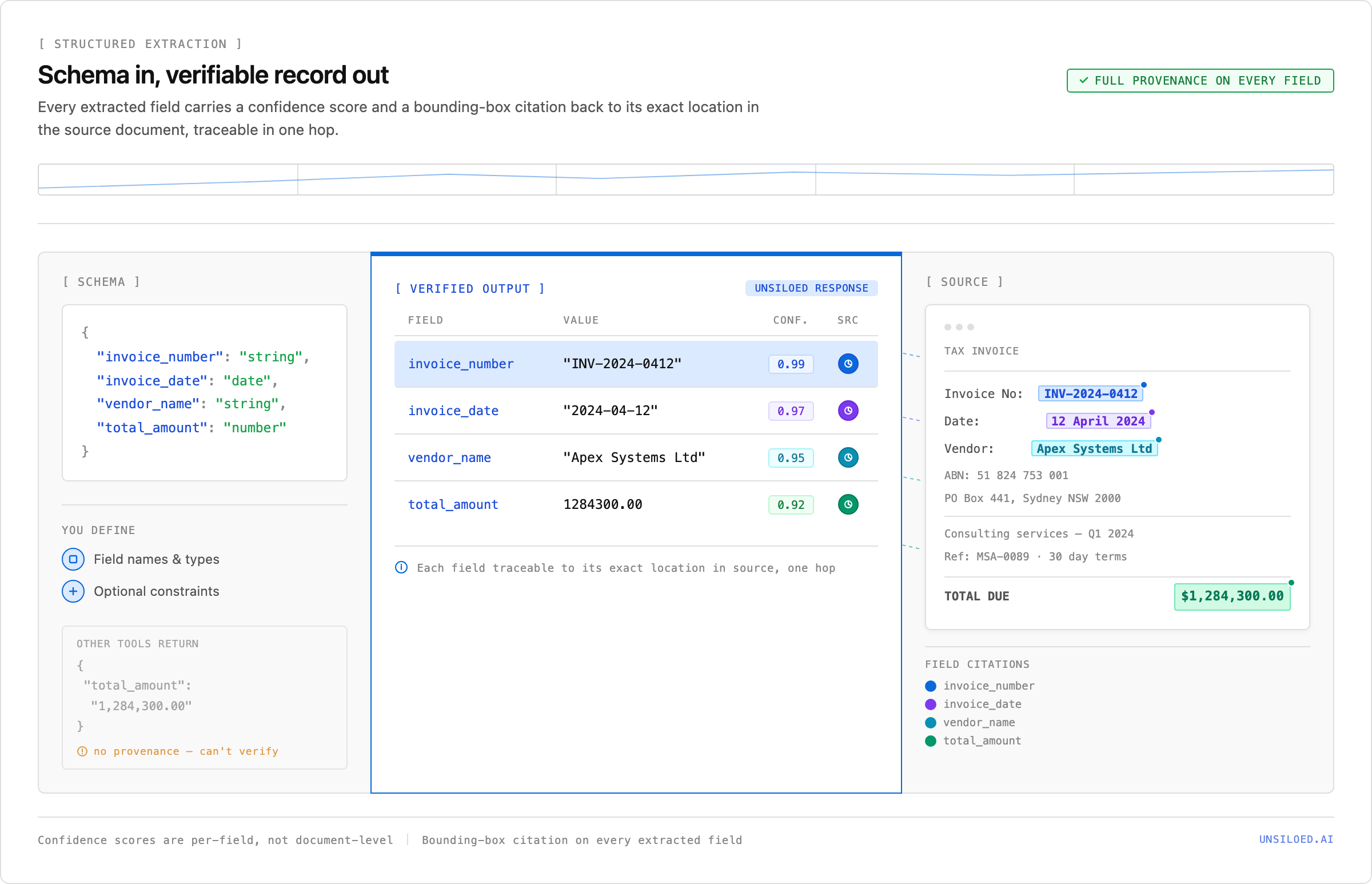
You define a schema, and Unsiloed returns each field with a confidence score and a citation that locates it in the source, so every value can be verified in one hop.
Both platforms accept a JSON schema and return typed output. You define the fields you need, submit a document, and get back structured JSON you can act on directly, without manual post-processing.
What Unsiloed adds is provenance on each value. With citations enabled, every field comes back with its confidence score and the bounding box that locates it in the source. A single field looks like this:
{
"invoice_number": {
"value": "INV-2024-0412",
"page_no": 1,
"score": 0.99,
"bboxes": [
{
"bbox": [139, 209, 280, 222],
"text": "INV-2024-0412",
"confidence": 0.99,
"page_width": 595.0,
"page_height": 842.0
}
]
},
"total_amount": {
"value": 1284300.0,
"page_no": 1,
"score": 0.92,
"bboxes": [
{
"bbox": [451, 612, 560, 628],
"text": "$1,284,300.00",
"confidence": 0.93,
"page_width": 595.0,
"page_height": 842.0
}
]
}
}The score is the per-field confidence, returned on every extraction by default, so you can triage uncertain values without re-reading the document. The bboxes array is the citation: it pins each value to an exact rectangle on the page, so a reviewer or an agent can jump straight to the source. Confidence ships by default; bounding-box citations are turned on with the enable_citations flag.
That is the gap with the alternative. LlamaExtract returns schema-conformant JSON, but per-field confidence scores and citations are not currently documented, and LlamaIndex lists verification and citations among planned features. For a pipeline that has to prove where each value came from, that difference is the deciding factor.
Pipeline Scope and Deployment
Unsiloed also covers the rest of the ingestion pipeline: a hosted workflow chunks, embeds, and stores documents in a vector index, so you can go from a raw file to a queryable index without wiring those stages together yourself. LlamaCloud offers the same managed indexing. Shipping RAG to production needs that whole chain to hold up, not just the parser.
Deployment is where teams handling sensitive documents should look closely. Unsiloed runs in the cloud and supports on-premise and air-gapped deployment across AWS, Azure, and GCP, so document data never has to leave your environment. LlamaCloud can also be self-hosted, but only on its Enterprise plans. For most teams, neither option is ruled out on deployment grounds, so the decision comes down to the output itself.
Where Each Tool Fits
- Unsiloed AI suits teams whose documents are high-stakes, where every extracted value needs a confidence score and a citation for audit, compliance, or agent verification.
- LlamaIndex suits teams already invested in its open-source ecosystem who want to stay within that stack.
The deciding factor is verifiability. If extracted values have to be checkable against the source, Unsiloed is built for it; LlamaIndex makes sense mainly when staying inside its ecosystem outweighs that.
Why Unsiloed AI is the Better Choice for Verifiable Document AI
The case for Unsiloed rests on what it returns, not on which features exist on either side:
- Verifiable extraction: every field returns a confidence score by default, with bounding-box citations on request, giving downstream systems and reviewers an evidence trail back to the source without extra tooling.
- Confidence on every parsed value: parsing attaches a confidence score and bounding box to each segment, so low-certainty regions are visible before they reach retrieval or extraction.
- Benchmark transparency: Unsiloed publishes a leading score on the public olmOCR-Bench, which is easier to validate against than a vendor's internal results.
- Deployment for regulated data: cloud, self-hosted, on-premise, and air-gapped options meet strict data-sovereignty requirements.
If you are already committed to the LlamaIndex ecosystem, LlamaCloud will do the job. But if you need to trust and audit every value a pipeline extracts, Unsiloed is built for that from the ground up.
Final Thoughts on Choosing a Document AI Platform
Unsiloed AI and LlamaIndex have converged on the same shape: managed pipelines that take a file and return structured, queryable data. The difference that remains is whether the output is verifiable. Unsiloed returns a confidence score on every value, with citations that locate each one in the source, so an agent or a compliance team can check each field against the original. If accurate, auditable extraction at scale matters to your workflow, try Unsiloed AI on your document set.
FAQ
How do I decide between LlamaIndex and Unsiloed AI?
Both are managed document-AI platforms, so start with what you need from the output. If every extracted value has to carry a confidence score and a citation for audit or compliance, Unsiloed AI is built for that by default. If you are already invested in the LlamaIndex ecosystem and verifiable output is not a hard requirement, LlamaCloud can cover the basics.
What's the main difference in how these products handle table extraction?
Both preserve table structure rather than flattening it into text. The difference is in the surrounding output: Unsiloed returns each table segment and extracted field with a confidence score, and can cite each value's position in the source, so values pulled from a table can be traced and triaged. LlamaParse preserves tables and provides bounding boxes through layout extraction, with per-field confidence and citations on extracted values not currently documented.
Is LlamaIndex only an open-source library?
No. The open-source LlamaIndex framework is still widely used, but document processing now runs on LlamaCloud, a managed platform that parses, extracts, classifies, splits, and indexes for retrieval. Unsiloed competes with that managed platform, and the difference is verifiable output: a confidence score on every value, with citations back to the source.
Can I deploy either tool on my own infrastructure?
Yes. Both offer cloud and self-hosted deployment, with LlamaCloud self-hosting available on Enterprise plans. Unsiloed additionally documents on-premise and air-gapped deployment across AWS, Azure, and GCP for teams with strict data-sovereignty requirements.
When does extraction verifiability actually matter?
It matters most when a wrong value causes downstream harm: a misread total on an invoice, a wrong date in a contract, or an incorrect figure in a financial filing. A confidence score lets you route uncertain fields to human review, and a bounding-box citation lets a reviewer or an agent confirm the value against the source in seconds. For regulated documents, that traceability is often a requirement rather than a convenience.


