
Best Document Intelligence APIs for Financial Services (April 2026)


Every financial services AI vendor claims their document processing is production-ready until you send them a scanned mortgage packet or a 150-page prospectus with nested tables. We mapped six document intelligence APIs against what matters in real financial workflows: layout understanding for multi-column filings, confidence scores for audit trails, and on-premise deployment when cloud processing isn't an option. If you need extraction that works beyond invoices and receipts, this ranking shows which tools hold up when document structure gets complicated.
TLDR:
- Financial institutions need document intelligence APIs that handle complex layouts like SEC filings and loan packets beyond basic receipts
- Unsiloed AI provides deterministic extraction with word-level citations and confidence scores for audit trails
- Vision-first architecture outperforms template-based OCR on multi-column reports and handwritten forms
- SOC 2 certification and on-premise deployment options meet strict banking compliance requirements
- Unsiloed AI processes millions of pages weekly for Fortune 150 banks with domain-specific models for finance
What is Document Intelligence for Financial Services?
Financial institutions deal with an enormous volume of documents: loan applications, bank statements, KYC forms, SEC filings, invoices, and regulatory submissions. Most of this data arrives unstructured, locked inside PDFs, scanned images, or dense multi-column reports that machines can't read reliably without help.
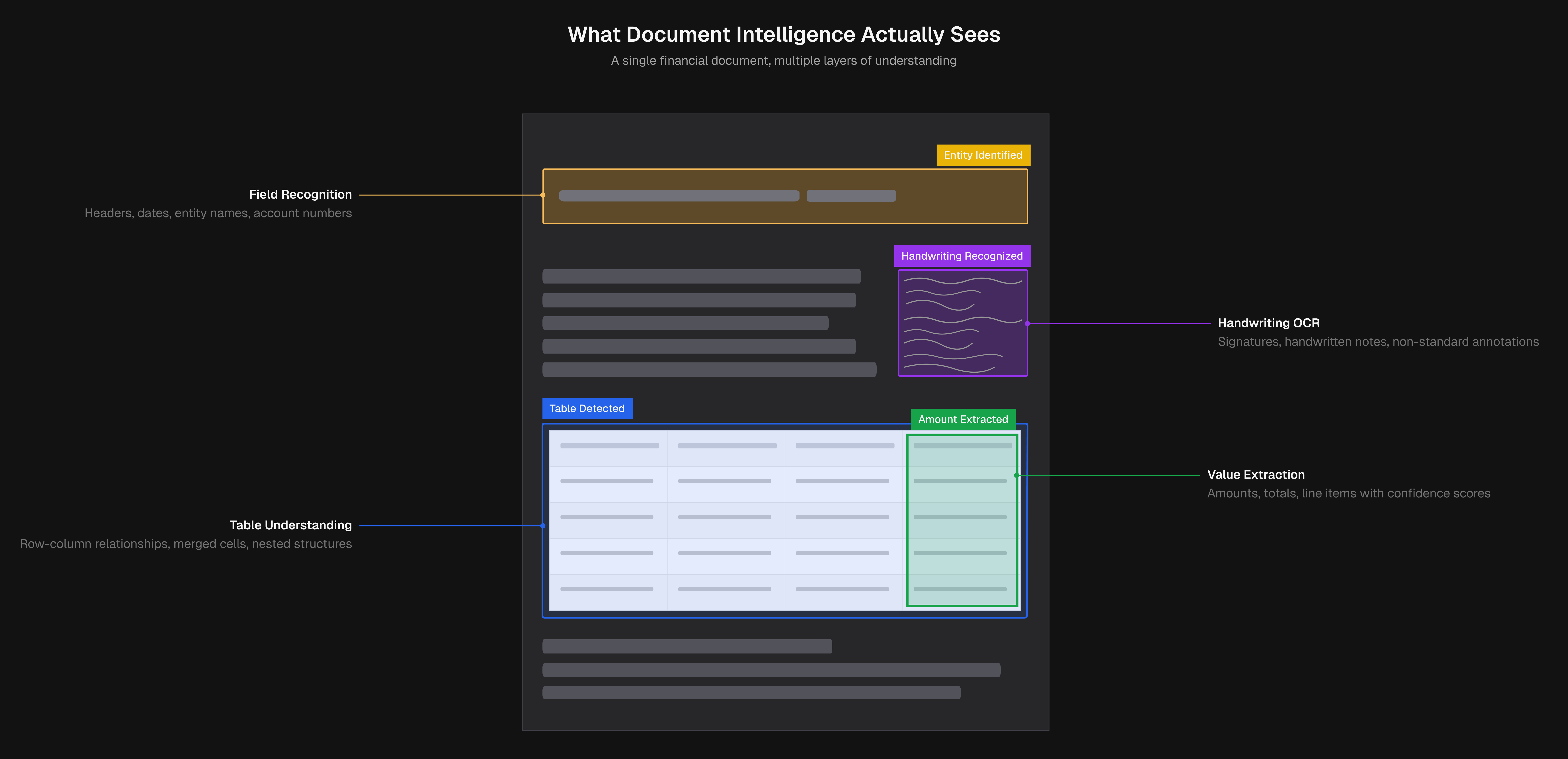
Document intelligence APIs solve this by combining OCR, computer vision, and AI to automatically extract, classify, and structure data from these documents. Where basic OCR reads text, document intelligence understands layout, reads tables correctly, identifies field relationships, and outputs structured JSON or Markdown that downstream systems can actually use.
In financial services, this matters because compliance workflows need auditable, traceable data, loan origination systems need accurate figures from complex forms, and risk teams need clean data from filings that may span hundreds of pages. Errors are costly.
Think of a document intelligence API as the infrastructure layer between your raw document intake and everything downstream: your LLMs, decision engines, compliance tools, or data warehouses.
How We Ranked Document Intelligence APIs for Financial Services
Not every document intelligence API is built for the specific demands of financial workflows. A tool that works fine for expense receipts may fall apart on a 200-page SEC filing or a scanned mortgage packet with inconsistent formatting. Rankings here are based on publicly available information, product documentation, and industry analyst reports instead of hands-on testing.
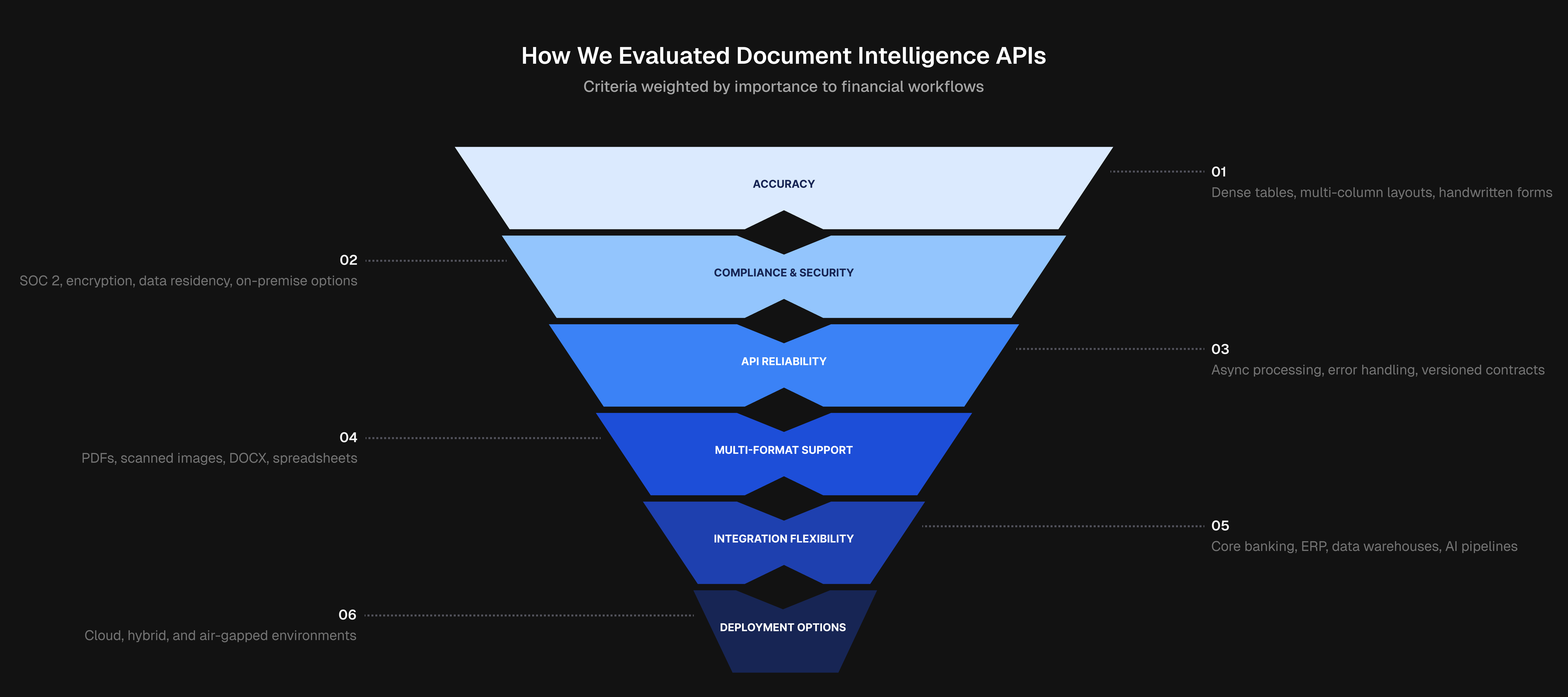
Here's what we weighted:
- Accuracy on financial document types, including dense tables, multi-column layouts, and handwritten or scanned forms
- Compliance and security standards, including SOC 2 certification, end-to-end encryption, data residency controls, and on-premise deployment options
- API reliability and production readiness, covering async processing, error handling, and stable versioned contracts
- Multi-format support across PDFs, scanned images, DOCX, spreadsheets, and other formats common in financial document workflows
- Integration flexibility with core banking systems, ERP tools, data warehouses, and AI pipelines
- Deployment options across cloud, hybrid, and air-gapped environments for institutions with strict data sovereignty requirements
A bank that can't run processing on-premise may be unable to use a given solution at all. Multi-page tables remain a persistent challenge across most document processing systems. A fintech with a RAG pipeline needs clean, structured output instead of raw text. That operating reality shaped every ranking here.
Best Overall Document Intelligence API for Financial Services: Unsiloed AI
When a Fortune 150 bank tests 15+ document processing solutions and one consistently wins, that's worth paying attention to. Unsiloed AI was built for this kind of high-stakes environment, where a misread table in a loan document or a dropped field from an SEC filing creates real downstream problems.
What Unsiloed AI Offers
- Layout-aware parsing that preserves hierarchical structure across financial documents, outputting deterministic Markdown and JSON
- Schema-driven extraction with word-level citations, bounding boxes, and confidence scores for full audit trails
- Vision models trained on financial document types: statements, filings, invoices, and contracts
- Production-grade infrastructure with async processing, SOC 2 certification, and on-premise deployment options
- Support for 20+ file formats including PDFs, spreadsheets, scanned images, and presentations
The architecture behind this matters. Our dual-stream vision model captures both semantic content and structural layout simultaneously, which is why it handles dense tables and multi-column filings where generic OCR breaks. Unsiloed AI makes unstructured financial documents LLM-ready without losing critical context. Domain-aware decoders for finance preserve context across complex hierarchies instead of flattening everything into raw text.
"The accuracy, particularly for tables, is great. We tried 15+ closed and open-source solutions in total. Unsiloed was the only one that seemed to work effectively." - Head of AI, Fortune 150 Bank
We process millions of pages weekly for Fortune 150 banks and NASDAQ-listed firms, consistently outperforming LlamaIndex, Gemini, Mistral, and Unstructured.io on public benchmarks. Every extracted field carries confidence scores and precise bounding boxes, giving compliance teams the explainability and traceability that regulatory workflows require.
For financial teams building RAG pipelines, automating loan processing, or extracting data from regulatory filings, this is infrastructure you can deploy in production.
Veryfi
Veryfi offers OCR and data extraction APIs built around transactional financial documents: receipts, invoices, and expense reports. If your workflow focuses on standardized purchasing documents at high volume, it covers the basics well.
Here is what the API covers:
- Pre-trained OCR APIs for receipts, invoices, checks, bank statements, W-2s, and W-9s
- Mobile capture via Veryfi Lens for smartphone document scanning
- Line-item extraction with fraud detection for purchasing workflows
- Support for 110+ data fields, 85 currencies, and 38 languages
Good for accounts payable automation and fintech expense management. Where it falls short is outside that lane. Multi-page loan applications, SEC filings, and mortgage packets involve hierarchical layouts, cross-document validation, and structural complexity that receipt-focused OCR tools aren't built to handle.
Hyperscience
Hyperscience targets enterprise document automation with a human-in-the-loop model, built for organizations that want AI assistance without removing human reviewers from the process.
What They Offer
- AI-powered classification and extraction with machine learning across document types
- Unified model for handwriting and typed text recognition
- Quality assurance feedback loops designed around existing data keying teams
- Banking integrations for mortgage processing and KYC verification workflows
Good for large financial institutions with existing manual review operations that want incremental automation layered on top of current processes.
The limitation is scalability. Human-in-the-loop architectures require exception handling, retraining cycles, and validation checkpoints at volume. Document chunking can break cross-references within complex contracts, creating downstream data integrity issues. That overhead compounds quickly in high-throughput environments where straight-through rates matter.
ABBYY
ABBYY has been in the document processing space for decades, offering FlexiCapture and Vantage for enterprise document automation.
- Pre-built document skills and OCR for invoices, forms, and structured documents
- Low-code/no-code Vantage interface for business users configuring workflows
- FlexiCapture for high-volume enterprise batch processing
- Integration connectors for RPA, BPM, and ECM systems
Good for enterprises with existing document management infrastructure that need pre-configured templates for standard financial forms. Where the gap appears is outside predictable, template-based workflows. Variable layouts, handwritten sections, and complex nested tables fall outside what template-driven OCR handles reliably. For diverse documents like prospectuses or regulatory filings, vision models that read document structure natively are a better fit.
Rossum
Rossum focuses on AI-powered invoice automation and accounts payable workflows, built around its proprietary Aurora extraction engine.
- Template-free extraction for transactional documents via the Aurora engine
- Three-way matching across purchase orders, invoices, and receipts
- Multi-channel document intake through email, API, and portal
- ERP integrations with SAP, Coupa, NetSuite, and Microsoft Dynamics
Good for finance departments automating purchase-to-pay workflows where documents are invoices and purchase orders with consistent, transactional structures.
The limitation shows up fast outside that lane. Rossum is not built for mortgage applications, credit reports, or regulatory filings. Banks and lenders need multimodal document understanding across complex hierarchical layouts, which invoice-focused tools simply don't cover.
Docsumo
Docsumo offers pre-trained extraction APIs aimed at financial services firms processing standardized documents.
- Pre-trained APIs for loan applications and insurance compliance documents
- Document classification with touchless processing
- Smart table extraction and validation workflows
- API integration with CSV, JSON, and XML output support
Good for smaller financial services firms where pre-built models align closely with specific, repeatable document types and validation needs are straightforward. For institutions processing diverse document portfolios at scale, flexible pricing plans matter as much as accuracy.
The gap appears with document variety. Pre-trained models optimized for loan forms don't transfer well to SEC filings, prospectuses, or multi-page financial statements with custom layouts. When documents require deep financial context and structural understanding, fixed model pipelines hit a ceiling fast.
Feature Comparison Table of Document Intelligence APIs
The table below maps each API against the capabilities that matter most in financial services workflows.
Feature | Unsiloed AI | Veryfi | Hyperscience | ABBYY | Rossum | Docsumo |
|---|---|---|---|---|---|---|
Vision-First Layout Understanding | Yes | No | No | No | No | No |
Template-Free Extraction | Yes | Yes | Yes | No | Yes | Yes |
Multi-Page Complex Documents | Yes | No | Yes | Yes | No | No |
Financial Domain Models | Yes | No | No | No | No | No |
Word-Level Citations | Yes | No | No | No | No | No |
Confidence Scores | Yes | No | Yes | No | Yes | Yes |
On-Premise Deployment | Yes | No | Yes | Yes | No | No |
SOC 2 Compliance | Yes | Yes | Yes | Yes | Yes | Yes |
API-First Architecture | Yes | Yes | No | No | Yes | Yes |
Schema-Driven Extraction | Yes | No | No | No | No | Yes |
Why Unsiloed AI is the Best Document Intelligence API for Financial Services
Most document intelligence APIs are built around a single workflow. Veryfi handles receipts. Rossum handles invoices. ABBYY handles template-driven batch processing. When a financial institution needs to process loan applications, SEC filings, mortgage packets, and KYC forms inside the same pipeline, those tools hit a wall fast.
Unsiloed AI covers the full range. Schema-driven extraction, layout-aware parsing, and domain models for finance mean you get accurate outputs whether the document is a two-page invoice or a 200-page regulatory filing. Every extracted field carries word-level citations and bounding boxes, giving compliance teams the audit trails they need without manual verification overhead.
For teams with strict data sovereignty requirements, on-premise and air-gapped deployment are supported. SOC 2 certification, end-to-end encryption, and a no-training-on-customer-data guarantee round out the security posture.
If you're building in financial services and need document processing that holds up in production, book a demo to see how Unsiloed AI handles your specific document types.
Final Thoughts on Financial Document Processing APIs
When you're automating document workflows for banking, the gap between basic OCR and production-ready financial document processing becomes obvious fast. Your loan systems need accuracy on handwritten forms, your RAG pipelines need structured outputs, and your compliance teams need verifiable extraction trails. Template-based tools can't scale across the document variety financial institutions actually deal with. Get in touch if you want to see how vision-first extraction handles your specific document types.
FAQ
How do I choose the right document intelligence API for my financial institution?
Start by mapping your actual document types and volume. If you process mainly standardized invoices or receipts, a receipt-focused API may work. If your workflows include loan applications, regulatory filings, and mortgage packets with varied layouts, you need vision models that understand document structure natively instead of template-based extraction.
Which document intelligence API works best for compliance and audit requirements?
Look for APIs that provide word-level citations, bounding boxes, and confidence scores for every extracted field. These features create audit trails that compliance teams can verify without manual re-checking. SOC 2 certification and on-premise deployment options matter if you handle sensitive financial data with strict regulatory oversight.
Can document intelligence APIs handle both scanned images and digital PDFs?
Yes, but accuracy varies widely between tools. OCR-based systems struggle with complex layouts in scanned documents, while vision-first models read document structure directly and handle both formats reliably. Test your specific document types, especially multi-column forms and dense tables, before committing to production deployment.
What's the difference between template-based and template-free extraction?
Template-based extraction relies on predefined document layouts and works well when processing the same form repeatedly. Template-free extraction uses machine learning to understand document structure dynamically, handling layout variations without configuration. Financial institutions with diverse document types need template-free approaches to avoid constant retraining.
When should I consider on-premise deployment instead of cloud-based APIs?
If your institution has data residency requirements, processes highly sensitive documents, or operates under regulatory frameworks that restrict cloud data transfer, on-premise or air-gapped deployment becomes necessary. Banks and compliance-focused financial firms often require this option for loan documents, KYC forms, and customer financial records.


