
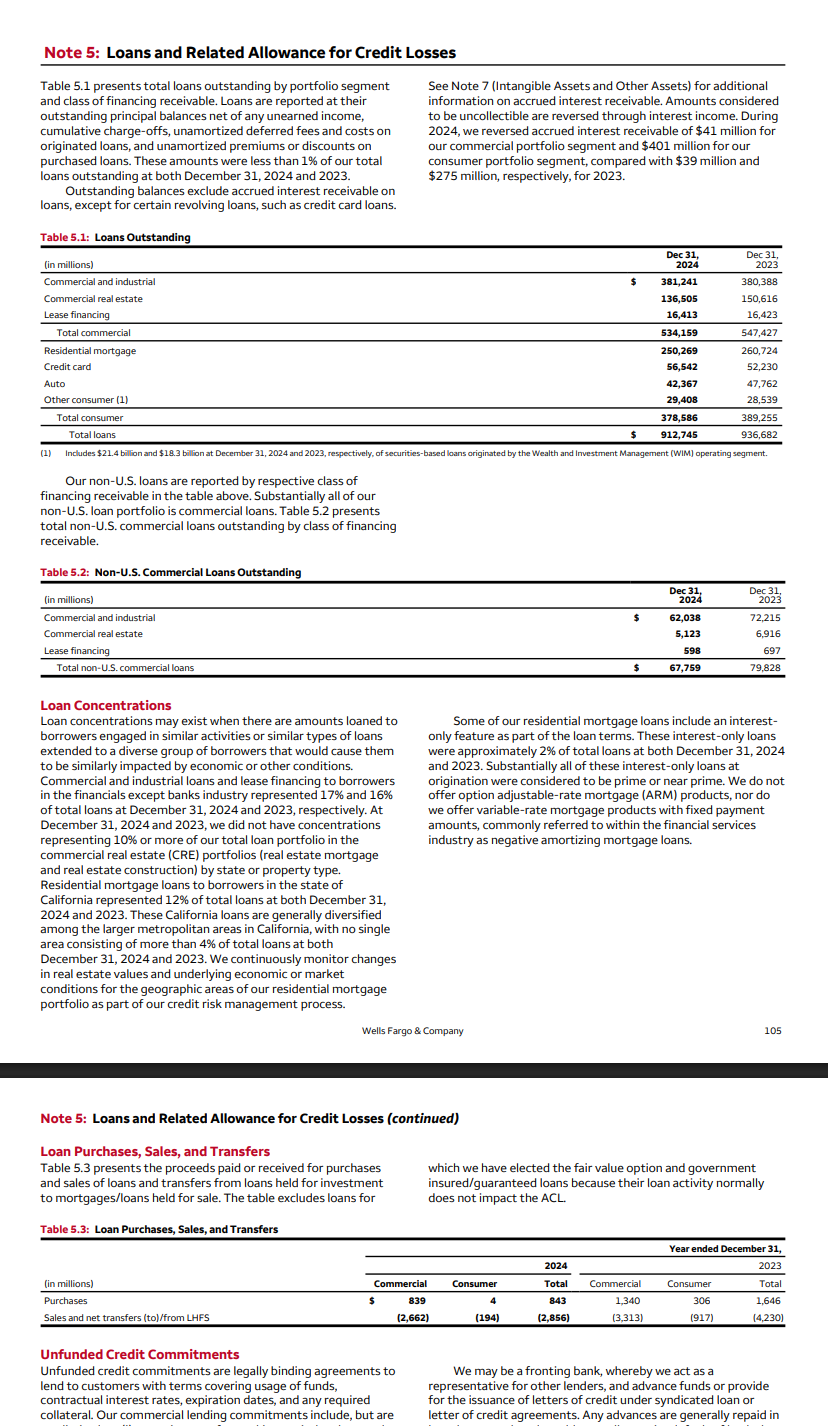
Why multi-page tables still break every extraction pipeline


Open a schedule of investments from any mid-sized fund's annual report. The table starts on page 12 and ends on page 17. It has 400+ rows, multi-level column headers, and a grand total row that only appears on the last page. Every page in between repeats the column headers but not the multi-level grouping row above them.
Three ways page boundaries break tables
Table extraction systems process documents page by page - each page is an independent unit. This works when every table fits on a single page. It fails on multi-page tables, which are ubiquitous in financial filings, insurance schedules, and regulatory appendices.
The first failure is header discontinuity. Page 12 has the full header: "Fair Value Measurements" spanning four sub-columns. Page 13 repeats only the sub-columns without the parent grouping. The hierarchical column structure is lost.
The second failure is row continuity. Page 14 ends mid-group - "Corporate Bonds - Investment Grade" rows are shown, but "High Yield" continues on page 15. Without knowing both pages belong to the same table, the parser creates two separate tables and the grouping context is gone.
The third failure is footer-versus-continuation ambiguity. A "Subtotal: $4.2B" row on page 14 might be a running subtotal within a larger table or the final row of a self-contained table. The parser cannot determine this from one page alone.
Why page-level processing creates this
PDF is a page-oriented format. Content is placed at absolute coordinates with no semantic markup indicating table continuation. The visual cue for humans is subtle - the absence of a bottom border on one page, a repeated header on the next. But these cues are inconsistent. Some documents repeat headers on continuation pages; others do not. Some add "(continued)" labels; others do not.
There is no reliable universal signal for table continuation. Any heuristic - matching column counts, header text, detecting continuation labels - works on some documents and fails on others. Documents with two different tables sharing identical column structures on adjacent pages would be incorrectly merged.
Prevalence in real financial filings
Cross-page tables are the norm for substantial filings. In SEC 10-K filings from large financial institutions, notes to financial statements routinely contain tables spanning 3-8 pages. Insurance schedules can span 20+ pages.
Every one of these tables is effectively invisible to page-level extraction. The parser produces multiple partial tables - each internally consistent but collectively fragmented.
Why cross-page stitching is hard to solve
Cross-page continuation is one of the few problems where the default architecture of most systems works against the solution. Page-level processing is the standard design choice, driven by memory efficiency, compute constraints, and PDF's page-oriented structure.
Multimodal language models can technically see multiple pages simultaneously - GPT-4o, Claude, and Gemini all accept multi-image inputs in a single request. But this does not solve the problem at production scale. Accuracy degrades as pages are added, structured output from dense financial tables becomes unreliable, and cost scales linearly with page count. In practice, most extraction pipelines still process pages independently for these reasons.
The robust solution is a post-extraction linking step that operates across pages - comparing column structures, detecting continuation signals, and merging fragments. This requires explicit engineering. The information needed to determine whether two page-level tables are actually one exists in the relationship between pages, and while a sufficiently large context window makes it theoretically visible, reliably extracting it demands purpose-built logic rather than general-purpose model scale.
At Unsiloed AI, we handle this through a parameter called merge_tables that triggers a dedicated cross-page reconciliation job. Rather than relying on any single heuristic, it evaluates multiple signals simultaneously: column structure alignment between adjacent pages, presence or absence of summary/footer rows, semantic boundary detection, repeated header patterns, row-group continuity, and continuation markers.
These signals are weighted contextually - a missing bottom border means something different in an insurance schedule than in a balance sheet. The result is a single, correctly structured table - not a collection of page-sized fragments that downstream systems have to guess how to reassemble


