
Unsiloed AI vs Reducto: Which is Better in April 2026?


Choosing between Reducto and Unsiloed AI matters most when your documents don't cooperate: dense financial statements where column relationships determine meaning, scanned clinical forms where field positioning drives interpretation, or legal contracts with nested sections that flatten into useless chunks downstream. Both tools move beyond basic OCR, but one corrects errors through multiple passes while the other processes image tokens and layout structure together in a single pass. For teams where extraction mistakes carry compliance risk, understanding how each system handles structure before errors reach your pipeline is the actual decision point.
TLDR:
- Unsiloed AI processes structure and content simultaneously with its Dual-Stream Vision Model, preventing table and chart errors before they occur
- Every extracted field includes word-level citations, bounding boxes, and confidence scores for full traceability back to source documents
- Domain-specific decoders for finance, healthcare, and legal preserve context that generic parsing tools flatten or lose
- On-premise and air-gapped deployment options keep your data in your environment when compliance requires it
- Unsiloed AI is built for enterprise-scale document processing, handling 10M+ pages weekly for Fortune 150 banks and NASDAQ-listed companies
What is Reducto?
Reducto is a document parsing API that converts unstructured files into structured JSON for use in AI workflows. Instead of treating documents as flat text, it approaches them as visual objects with contextual meaning, combining vision models with OCR to handle formats like PDFs, spreadsheets, and presentations.
On top of that base layer, Reducto adds what it calls an Agentic OCR framework. The idea is to catch last-mile parsing errors that the vision model misses on its own, running a correction pass to improve output quality before returning results. It's a reasonable approach to a real problem: even good vision models slip up on messy layouts, and having a recovery layer matters in production.
For teams looking for a straightforward parsing API to get documents into JSON, Reducto covers the basics. Where things get more interesting is when you compare it against tools built with more opinionated infrastructure around accuracy, extraction schemas, and production reliability.
What is Unsiloed AI?
Unsiloed AI builds the unstructured data interface for LLMs and AI agents. Where most parsing tools treat documents as text extraction problems, Unsiloed AI treats them as visual, structural objects that require a fundamentally different approach to understand.
The core sits on a vision-first architecture that combines computer vision, OCR, and multimodal models to convert complex documents into deterministic, machine-readable outputs. Real-world documents don't cooperate: dense tables, embedded charts, scanned forms, multi-column layouts, and inconsistent formatting all break tools that rely on text extraction alone.
Customers include Fortune 150 banks, NASDAQ-listed companies, and 10+ YC startups in finance, legal, and healthcare, where getting a table wrong carries real consequences. Unsiloed AI currently processes over 10 million pages per week, and that scale has shaped how the product is built.
Four core APIs drive it:
- Parsing produces structured Markdown and JSON from any document type.
- Schema-based extraction returns word-level citations, bounding boxes, and confidence scores.
- Classification routes documents by type using visual and semantic signals.
- Splitting breaks large or merged files into logical sections.
Together, they sit as the infrastructure layer before your LLMs, agents, or RAG pipelines, so downstream systems work from clean, reliable data.
Multimodal Document Understanding
Both tools reach beyond plain OCR, but the architectural decisions they've made lead to meaningfully different outcomes depending on what your documents actually look like.
The competitor's Parse API combines traditional computer vision with Vision-Language Models to produce LLM-ready output from 30+ document formats. For tricky cases, its Agentic OCR feature runs a correction pass on top of the base model output, catching errors the initial pass misses. The company reports over 20 percentage points of improvement on datasets like RD-TableBench, and the approach works well for standard business documents where text extraction is the primary goal. The tradeoff is cost: Agentic OCR runs at roughly twice the credit usage. For teams processing dense plots, complex charts, or documents where visual hierarchy carries meaning, the system can show gaps in how those elements are interpreted and related.
Unsiloed AI takes a different approach at the architecture level. Instead of running sequential passes, we built a proprietary Dual-Stream Vision Model that processes both semantic content and structural layout simultaneously. The model feeds actual image tokens (extracted text and numbers plus their visual representation), which captures visual context alongside the document's hierarchical structure in a single pass.
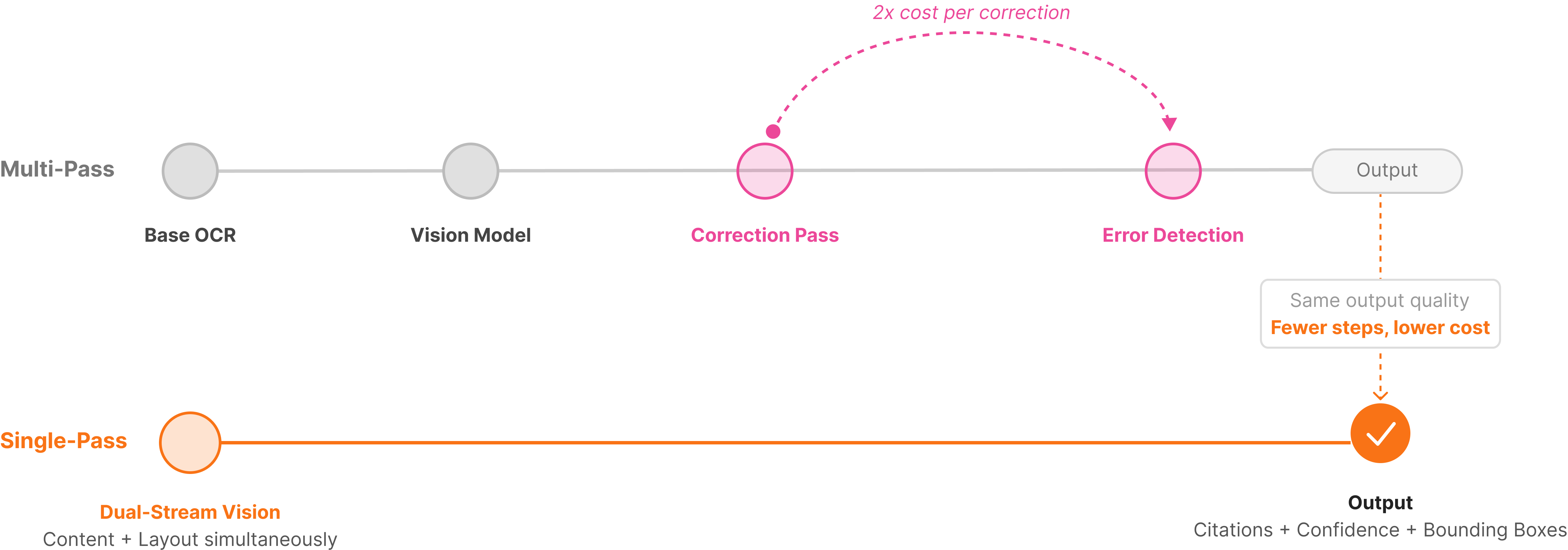
The practical difference shows up most clearly in documents where structure carries meaning: a financial table where column relationships matter, a clinical form where field positioning determines interpretation, or a slide deck where a chart's legend is separated from the data it describes.
That simultaneous understanding of layout and content is why Unsiloed consistently performs in finance, legal, and healthcare, where misreading a chart or flattening a nested table creates real downstream errors. Every extracted element returns with word-level citations and bounding boxes, so you can trace any output back to its exact location in the source document.
Document Structure and Hierarchy Preservation
Both tools segment documents into identifiable layout types, but how they represent relationships between those elements is where they diverge.
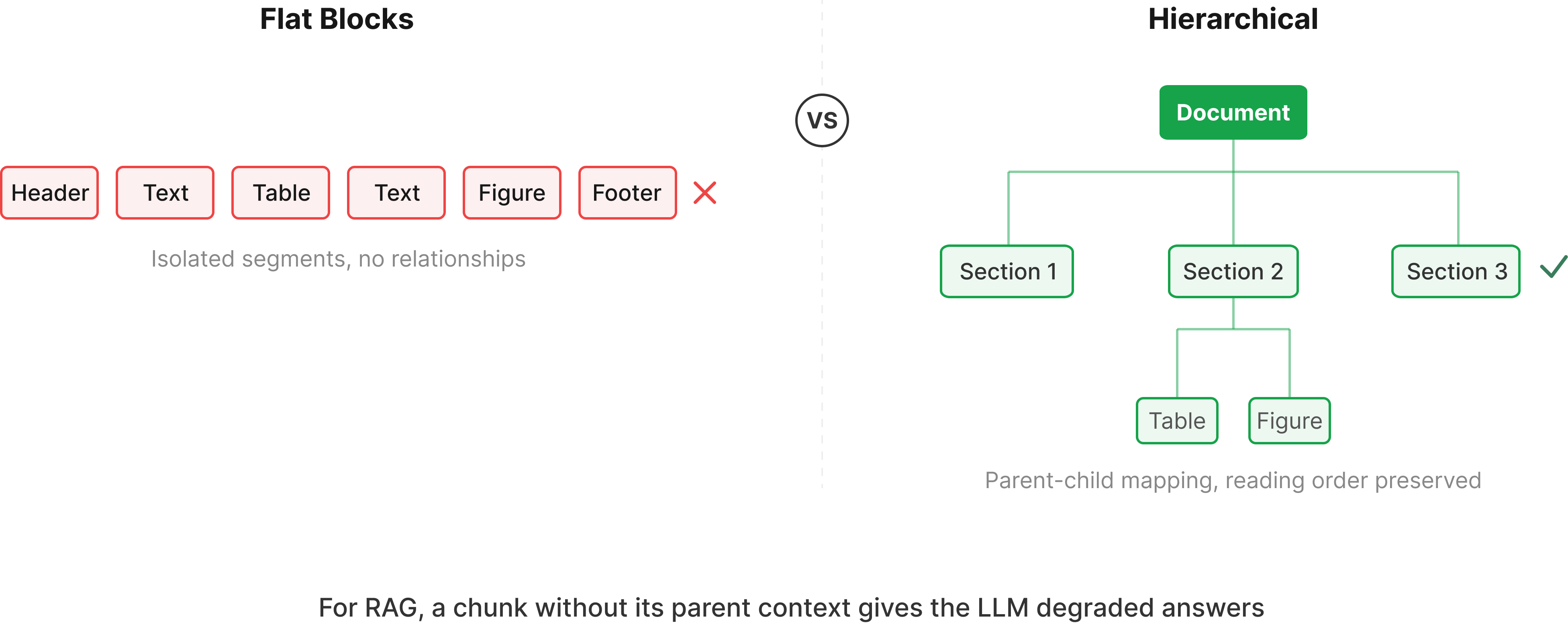
The competitor breaks documents into discrete blocks: headers, tables, text, figures, each with bounding boxes and segment labels. Its chunking system is configurable, with a variable chunk mode designed for RAG. For flat or lightly structured documents, this works well. Where it gets harder is when documents have nested sections, parent headers that govern multiple child blocks, or table structures that span context across the page. Reconstructing those relationships downstream usually means additional post-processing on your end.
Unsiloed AI generates hierarchical chunks with parent-child mapping built in from the start. Parsing preserves reading order, visual hierarchy, and layout relationships natively, so the output already reflects how the document is logically organized, not simply what appears on the page. Tables, images, charts, formulas, and headers are all understood as first-class elements in context, not isolated blocks.
Domain-aware decoders for finance, healthcare, and legal extend this further. A financial filing, a clinical form, and a contract each have their own structural logic, and our decoders preserve that domain-specific context instead of flattening everything into a generic hierarchy.
For RAG in particular, chunk structure directly affects retrieval quality of the source document. If a retrieved chunk has lost its relationship to a parent section, or if a table row has been separated from its column headers, the context the LLM receives is degraded before it even starts reasoning.
Capability | Reducto | Unsiloed AI |
|---|---|---|
Layout segmentation | Yes | Yes |
Bounding boxes | Yes | Yes, word-level |
Native parent-child hierarchy | No | Yes |
Domain-aware structure preservation | No | Finance, legal, healthcare |
RAG-optimized chunk output | Configurable | Built-in |
Extraction Accuracy and Determinism
Extraction reliability separates tools that work in demos from those that hold up in production. The gap here is less about feature parity and more about how each system handles errors before they reach your pipeline.
The competitor provides confidence scores and word-level citations, with specialized models hand-tuned for citation tasks. Its Agentic OCR framework runs multi-pass correction loops, and the company reports 99.24% accuracy in clinical SLA benchmarks. That covers most general document processing use cases well. The structural issue is that layering a correction pass on top of a base model means hallucinations on dense financial tables or structured forms can still slip through, and the variable cost of agentic processing makes outputs harder to budget and predict at scale.
Unsiloed AI takes a different position. Schema-driven extraction produces strict, deterministic outputs by design. Every field returns a confidence score, word-level citation, and bounding box, so any extracted value is fully traceable back to its exact location in the source. The vision model understands structure upfront instead of correcting after the fact, which prevents hallucinations on tables and numbers before they occur. A built-in reinforcement learning pipeline uses those confidence scores to continuously sharpen accuracy over time.
For finance, legal, and healthcare teams, that distinction is real. An extraction error in a loan document or a clinical record is a compliance risk, not a parsing inconvenience.
Production Infrastructure and Deployment
Both tools cover standard cloud deployment. The differences surface when requirements get more specific.
The competitor runs as a cloud API with credit-based pricing and automatic cost routing that downgrades simpler pages to cheaper processing paths. It holds SOC 2 Type II and HIPAA certifications with a zero-retention processing guarantee, which covers most SaaS compliance needs. Teams requiring on-premise or air-gapped deployment will find options limited here.
Unsiloed AI supports cloud-native, on-premise, air-gapped, and hybrid configurations. Customer data is never used to train base models, and when required, all processing and improvements stay within the customer's private instance.
API and Infrastructure Design
Both tools handle asynchronous processing for large documents. Unsiloed AI is built for enterprise-scale throughput, with REST APIs on stable versioned contracts and predictable error handling designed for production integrations. You get quota tracking, clean status responses, and consistent behavior across job types.
For finance, legal, or healthcare teams where data cannot touch shared infrastructure, deployment flexibility is a real decision point.
Why Unsiloed AI is the Better Choice
For teams processing standard business files where basic text extraction is sufficient, the competitor handles the job adequately.
But when accuracy directly affects compliance, financial outcomes, or patient records, the architectural differences covered in this article translate into real production risk. The Dual-Stream Vision Model processes image tokens alongside layout structure simultaneously in a single pass, which is why it holds up on dense tables, charts, and complex forms where other tools degrade. Schema-driven extraction returns deterministic outputs with word-level citations and bounding boxes every time. Hierarchical indexing and domain-aware decoders for finance, legal, and healthcare preserve the context your RAG pipeline actually needs.
For enterprises where data sovereignty is non-negotiable, on-premise and air-gapped deployment options are available as first-class choices.
If accurate, traceable document processing at scale is what you're building toward, reach out at hello@unsiloed-ai.com.
Final Thoughts on Building Reliable Document Pipelines
Choosing between Unsiloed AI or Reducto depends on whether your documents contain structure that breaks text extraction tools. Our approach processes image tokens alongside layout hierarchy, so dense tables and complex forms come through with preserved relationships and full citations. Most teams start with a demo using their actual files to see how the vision model handles edge cases. Whether you process 10,000 pages or 10 million per week, the architecture delivers consistent outputs without hallucinations on numbers or tables.
FAQ
How should I decide between these two document parsing tools?
Start by looking at your document complexity and accuracy requirements. If you're processing standard business files where basic text extraction is enough, either tool will work. If you're handling dense financial tables, clinical forms, or legal documents where extraction errors create compliance risks, you need a vision-first architecture that understands structure upfront instead of correcting it after the fact.
What's the core difference in how these products handle complex tables?
The competitor runs sequential correction passes on top of base model output to catch errors, which can miss hallucinations in dense structured data. Unsiloed AI uses a Dual-Stream Vision Model that processes image tokens and layout structure simultaneously in a single pass, preventing hallucinations on tables and numbers before they occur. Every extracted value includes word-level citations and bounding boxes for full traceability.
Who is each product best suited for?
The competitor works well for teams processing general business documents in cloud environments where deployment flexibility isn't a constraint. Unsiloed AI is built for AI teams at Series B+ companies and enterprises in finance, legal, and healthcare where accuracy directly affects compliance outcomes, and where on-premise or air-gapped deployment may be required for data sovereignty.
What should I consider when migrating document processing to a new system?
Check whether the tool preserves parent-child hierarchy natively or requires post-processing on your end to reconstruct document structure. For RAG pipelines, retrieval quality depends on whether chunks maintain their logical relationships to parent sections and sibling elements. You'll also want to confirm deployment options match your data residency requirements, especially if processing cannot occur on shared infrastructure.