
Unsiloed AI vs Extend: Which is Better in April 2026?


When you're comparing document extraction platforms, the decision goes beyond accuracy percentages. It's about whether your pipeline needs deterministic outputs you can audit field by field or an agentic approach that fine-tunes over time with human feedback. Both tools handle complex documents, but they differ sharply on explainability, format support, and deployment options. Here's what you need to know about each before you commit to an infrastructure dependency your team will build on top of.
TLDR:
- Choose deterministic extraction when you need field-level audit trails with confidence scores and word-level bounding boxes tracing every value back to source documents: critical for finance, legal, and healthcare compliance requirements.
- Process 20+ file formats natively including PDFs, DOCX, PPTX, and Excel without conversion overhead, while the alternative focuses primarily on PDFs requiring preprocessing for other document types.
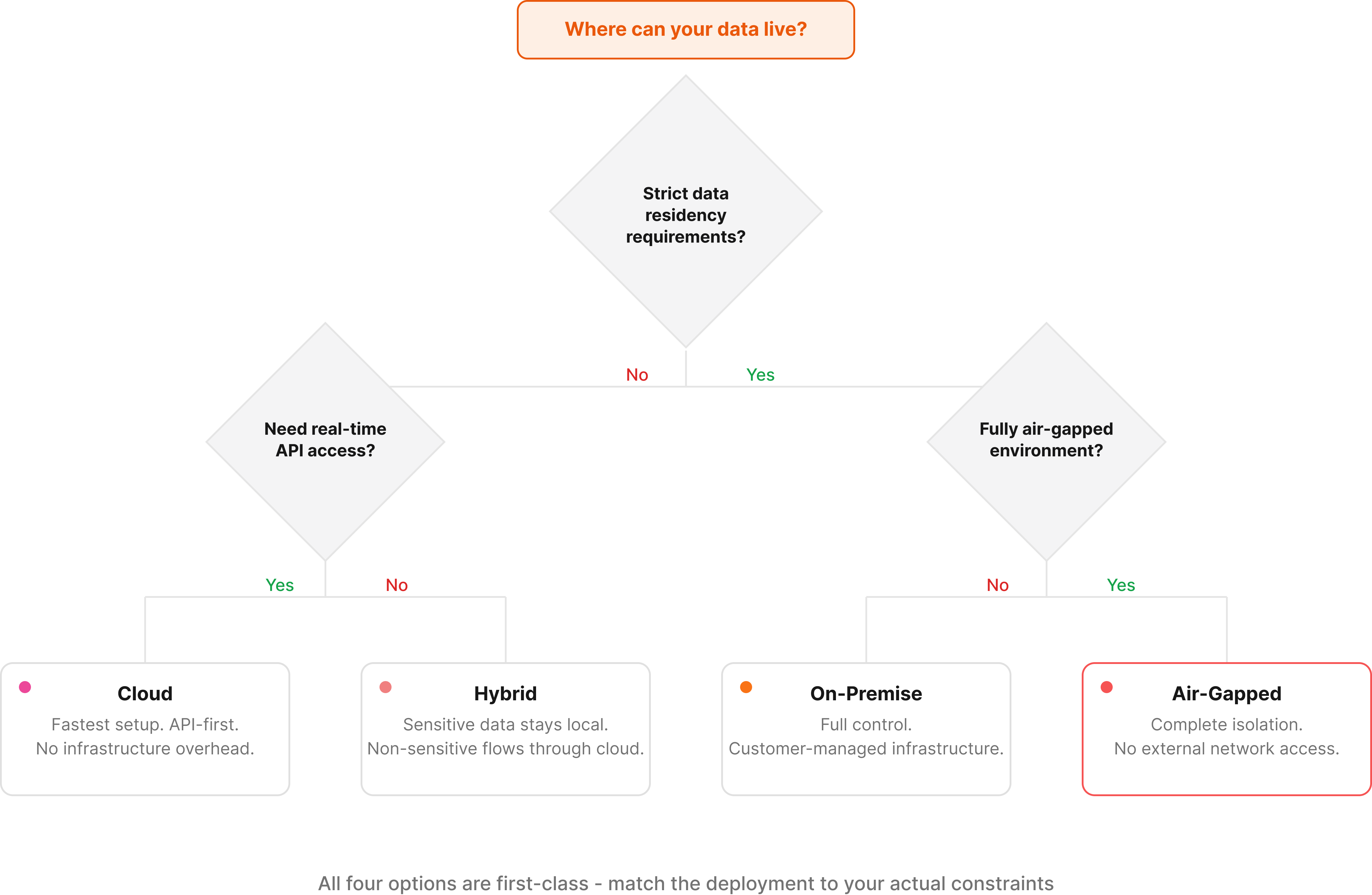
- Deploy on-premise, air-gapped, or hybrid with SOC 2 compliance and zero data retention. Unsiloed AI handles millions of pages weekly for Fortune 150 banks without sending your data to third-party model providers.
- Get production-ready infrastructure with asynchronous processing, strict JSON Schema validation, and nested object support instead of managing ongoing fine-tuning and human-in-the-loop correction cycles.
- Verify extraction quality with dual-stream vision models that outperform LlamaIndex, Gemini, Mistral, and Unstructured.io on complex document benchmarks, with no agentic post-hoc correction layers introducing output variability.
What is the Alternative?
The alternative is a document processing company founded in 2023. Its core focus is extracting structured data from complex documents, targeting technical teams that need reliable document processing APIs they can build on top of.
The product uses agentic OCR combined with vision-language models to handle documents with irregular formatting, handwriting, and tables. Instead of relying on a single model, it uses an ensemble approach that combines multiple LLMs with proprietary context engineering to improve output consistency across document types.
The company claims 99%+ accuracy on handwriting, tables, and mixed-format documents. That's a notable benchmark for any document processing tool, and ensemble methods are a reasonable way to chase it. The tradeoffs of that architecture, though, such as latency, cost per call, and output determinism, matter a lot when you're building production pipelines at scale. Those are worth understanding before committing to an infrastructure dependency.
What is Unsiloed AI?
Unsiloed AI is the unstructured data interface for LLMs and AI agents. Where most document tools stop at text extraction, we go deeper: our vision-first, layout-aware systems combine computer vision, OCR, and multimodal models to produce deterministic, machine-readable outputs that hold up in production.
The core of what we do is four APIs:
- Parsing: converts complex documents into structured, hierarchical Markdown and JSON while preserving reading order, tables, images, and visual layout
- Extraction: pulls specific fields using custom JSON schemas, with confidence scores and word-level bounding boxes tied back to the source document
- Classification: categorizes documents by type using both visual and semantic signals to route them correctly
- Splitting: breaks large or multi-document files into logical sections using layout, content, or rule-based logic
We support 20+ file formats including PDFs, DOCX, PPTX, Excel, and images. The system is built for high-throughput workloads with asynchronous processing, stable versioned REST APIs, and on-premise deployment for teams with strict data requirements. We are backed by Y Combinator and process millions of pages weekly for Fortune 150 banks, NASDAQ-listed companies, and 10+ YC startups.
Accuracy and Extraction Quality
Accuracy claims are easy to make and hard to verify. So let's look at what's actually happening under the hood.
The competitor benchmarks AWS Textract, Google Vision, and Azure Document Intelligence at 70-80% typical accuracy on handwriting, and positions its 99%+ claim as the result of ensemble methods: multiple LLMs combined with a proprietary VLM correction layer. For handwriting-heavy documents or tables with merged cells, that approach can work well. The tradeoff is transparency. An agentic correction layer that patches outputs post-hoc gives you less visibility into why a value was extracted a certain way, which matters when you need to audit results. Independent OCR accuracy benchmarks show substantial variation across providers and document types.

For teams building in finance, legal, or healthcare, "probably correct" isn't a production standard. You need to know exactly where a value came from and how confident the model is.
That's where our approach differs. Every field Unsiloed AI extracts includes a confidence score, word-level bounding boxes, and a citation mapped back to the source document. Our dual-stream vision model captures semantic content and structural layout simultaneously instead of correcting mistakes after the fact. We also have domain-aware decoders built for finance, healthcare, and legal documents to preserve context and hierarchy through extraction. We consistently outperform LlamaIndex, Gemini, Mistral, and Unstructured.io on public benchmarks for complex document types.
Infrastructure and Deployment Options
The right extraction tool is about what happens when you need to deploy it inside a compliance-sensitive environment, scale it to millions of pages, or hand it off to a security team.
The Competitor
The competitor packages parsing, classification, extraction, splitting, and markdown conversion into one end-to-end pipeline. Low-code tooling lets teams review outputs and feed corrections back into fine-tuned models, which is a reasonable workflow for iterating toward better accuracy over time. That said, the model tuning and evaluation loop adds ongoing maintenance overhead that not every team wants to own. Organizations with strict deployment requirements, including air-gapped environments, on-premise infrastructure, or zero data retention policies, may find the available options limited.
Unsiloed AI
We built our infrastructure to meet production requirements without asking your team to manage the underlying complexity. A few specifics worth knowing:
- Asynchronous processing handles large and multi-page documents without blocking your pipeline
- On-premise, air-gapped, and hybrid deployments give organizations full control over where data lives and how it's processed
- SOC 2 compliance, end-to-end encryption, and strict access controls meet enterprise security requirements out of the box
- Customer data is never used to train base models
- Clean REST APIs with stable versioned contracts and predictable error handling keep integrations reliable as we ship updates
- Our confidence score-based reinforcement learning pipeline improves accuracy continuously without requiring manual fine-tuning or evaluation overhead on your side
For teams in finance, legal, or healthcare, the deployment model is as important as the model itself.
Schema Definition and Extraction Control
Schema versioning and confidence thresholds matter, but production trust comes down to whether your extractions are auditable and deterministic run to run.
The Alternative
Extend includes automated evaluation that generates accuracy reports at field and document levels, plus schema versioning with draft, publish, and pin states. A production validation layer flags extractions below confidence thresholds for human review, useful for workflows where zero-touch processing introduces unacceptable risk. Multiple processing modes let you trade off between latency, cost, and accuracy depending on the job.
The catch is that an agentic extraction approach that patches outputs through correction layers can introduce variability in the final output. Teams requiring field-level determinism will need additional validation work on top of what the tool provides.
Unsiloed AI
Our extraction API is built on strict JSON Schema with deterministic outputs by default. Schemas require typed fields, required field declarations, and additionalProperties: false at every object level. Following extraction schema best practices guarantees clean, structured data from complex documents.
Every extracted field returns:
- A confidence score between 0 and 1
- Word-level citations tied to the source document
- Dual-level bounding boxes covering both the document segment and the precise OCR text location
You can trace any value back to exactly where it appeared in the original document, down to pixel coordinates. We support nested objects, arrays, and complex hierarchical schemas covering invoice line items, SEC filing tables, clinical record structures, and anything else with repeating or nested data.
For compliance-sensitive industries, the audit trail is the feature.
Feature | Alternative | Unsiloed AI |
|---|---|---|
Extraction Approach | Ensemble method using multiple LLMs with agentic correction layers that patch outputs post-hoc | Dual-stream vision model that captures semantic content and structural layout simultaneously with deterministic outputs |
Output Transparency | Accuracy reports at field and document levels with confidence thresholds for human review flagging | Every field includes confidence scores, word-level bounding boxes, and citations mapped back to source document with pixel-level coordinates |
File Format Support | Primarily PDFs including structured documents, degraded scans, handwriting, signatures, tables, and images | Native support for 20+ formats including PDFs, DOCX, PPTX, Excel, images without preprocessing or conversion steps |
Deployment Options | Limited options for air-gapped environments and strict data residency requirements | On-premise, air-gapped, and hybrid deployments with SOC 2 compliance, end-to-end encryption, and zero data retention policies |
Schema Control | Schema versioning with draft, publish, and pin states plus multiple processing modes trading off latency, cost, and accuracy | Strict JSON Schema with typed fields, required declarations, and additionalProperties: false at every object level supporting nested objects and arrays |
Model Training | Low-code tooling for human-in-the-loop review and corrections fed back into fine-tuned models requiring ongoing maintenance | Confidence score-based reinforcement learning improves accuracy continuously without manual fine-tuning overhead; customer data never used for base model training |
Best For | Teams processing primarily handwritten documents who want to manage custom fine-tuning workflows internally | Production-grade extraction across document types requiring determinism, complete auditability, and compliance-ready infrastructure |
Document Format Support and Processing Capabilities
Both tools handle complex documents, but the range of what each can ingest differs in ways that matter depending on your data sources.
The Competitor
The competitor handles structured PDFs, degraded scans, handwriting, signatures, tables, and images well. Its extraction, classification, and splitting processors target over 95% accuracy across those formats, and the document splitter can identify distinct sections based on user-defined instructions.
The limit is format breadth. Teams working primarily with PDFs will find it capable, but if your pipeline touches presentations, spreadsheets, or other file types, you'll likely need to convert them before they enter the pipeline - adding preprocessing work your team has to own.
Unsiloed AI
We support 20+ file formats natively: PDFs, DOCX, PPTX, Excel spreadsheets, images, and more. No conversion step required. Our parsing API identifies and classifies every element type in a document, including:
- Text, titles, section headers, footnotes, page headers, and page footers
- Tables, pictures, charts, plots, and formulas
- List items and captions
Reading order and visual hierarchy are preserved across all of these. We accept both direct file uploads and presigned URLs from S3, GCS, and Azure Blob, so documents already in cloud storage route directly into the pipeline without extra handling.
For teams dealing with mixed document types, the difference between native support and preprocessing overhead adds up fast at scale.
Why Unsiloed AI is the Better Choice
If your team processes primarily handwritten documents and wants a human-in-the-loop fine-tuning loop, the alternative is worth considering. That's a real use case and they've built around it.
For everyone else building production document workflows, the choice is clearer. Unsiloed AI gives you deterministic outputs, word-level citations, full audit trails, and native support for 20+ file formats without preprocessing overhead. The infrastructure handles on-premise, air-gapped, and cloud deployments out of the box. SOC 2 compliance, asynchronous processing, and strict schema extraction mean your pipeline is audit-ready before you ship.
Most teams don't have months to spend on document ingestion. Unsiloed AI is built so you don't have to.
Final Thoughts on Choosing Document Processing Solutions
If handwriting is your primary challenge and you want to manage model tuning internally, the alternative workflow could fit. For teams that need production-grade extraction across document types, the architectural differences matter: we built for determinism, native format support, and complete auditability from day one. Your extractions come with confidence scores and word-level citations that trace back to source documents. Book a demo and bring your hardest documents.
FAQ
How do I decide between Unsiloed AI and the alternative if I need document extraction?
Start with your document types and deployment requirements. If you're processing primarily handwritten forms and want to manage a fine-tuning loop yourself, the alternative approach makes sense. If you need deterministic outputs with full audit trails across 20+ file formats, on-premise deployment options, and production-ready infrastructure without ongoing model maintenance, Unsiloed AI is the better fit.
What's the main difference in how the two products handle extraction accuracy?
The alternative uses an ensemble approach with multiple LLMs and agentic correction layers to patch outputs after extraction, which can introduce variability. Unsiloed AI uses a dual-stream vision model that captures semantic content and structural layout together from the start, returning every field with confidence scores, word-level bounding boxes, and citations back to the source document for full traceability.
Can I deploy either solution in an air-gapped or on-premise environment?
Unsiloed AI supports on-premise, air-gapped, and hybrid deployments out of the box with SOC 2 compliance and zero data retention guarantees. The alternative's deployment options may be more limited for teams with strict data residency or regulatory requirements, so you'll want to verify what's available before committing.
Who should use the alternative instead of Unsiloed AI?
Teams that work exclusively with handwritten documents and want to build custom fine-tuning workflows with human-in-the-loop review cycles will find the alternative's low-code tooling useful. That's a specific use case they've designed around.
How much preprocessing work is required before processing documents?
Unsiloed AI handles 20+ file formats natively including PDFs, DOCX, PPTX, Excel, and images without conversion steps. The alternative focuses primarily on PDFs, so teams working with presentations, spreadsheets, or mixed document types will likely need to add preprocessing before documents enter the pipeline.