
Top Multimodal Data Extraction Tools for Enterprise AI Agents (April 2026)


Building AI agents means feeding them structured data, but structured data APIs for documents rarely deliver on complex layouts. Your parser sees a multi-column PDF and returns text in the wrong order. It hits a nested table and flattens the hierarchy. It encounters a chart and skips it entirely. Standard OCR doesn't cut it when you need JSON that your agents can trust in production. We tested six tools on accuracy, auditability with bounding boxes, format coverage, and whether they handle the messy documents finance, legal, and healthcare teams process daily.
TLDR:
- Multimodal extraction turns complex documents into structured, machine-readable formats AI agents can use
- You need word-level bounding boxes and confidence scores to audit extracted data in finance, legal, and healthcare
- Vision-first tools outperform text-only parsers on tables, charts, and nested layouts by 40%+
- Unsiloed AI processes 10M+ pages weekly for Fortune 150 banks with deterministic, citation-backed outputs
What is Multimodal Data Extraction for Enterprise AI Agents?
Most enterprise documents don't cooperate. A financial statement has nested tables. A loan agreement has footnotes referencing clauses three pages back. A clinical form mixes handwritten fields with printed text. Standard OCR reads characters. It doesn't read documents. Multimodal data extraction goes further.
Multimodal data extraction goes further. It converts complex, unstructured documents into structured, machine-readable formats by understanding layout, visual hierarchy, and semantic relationships beyond raw text alone. A table stays a table. A chart gets interpreted. A multi-column PDF gets read in the right order. The output is JSON or Markdown that an AI agent or LLM can actually work with reliably.
The intelligent document processing market is projected to grow from $3.0B in 2025 to $54.7B by 2035, driven by enterprises building AI agent workflows that need accurate, structured inputs at scale. AI agents are only as good as the data they receive. Feed them broken or structure-less text and the whole pipeline fails.
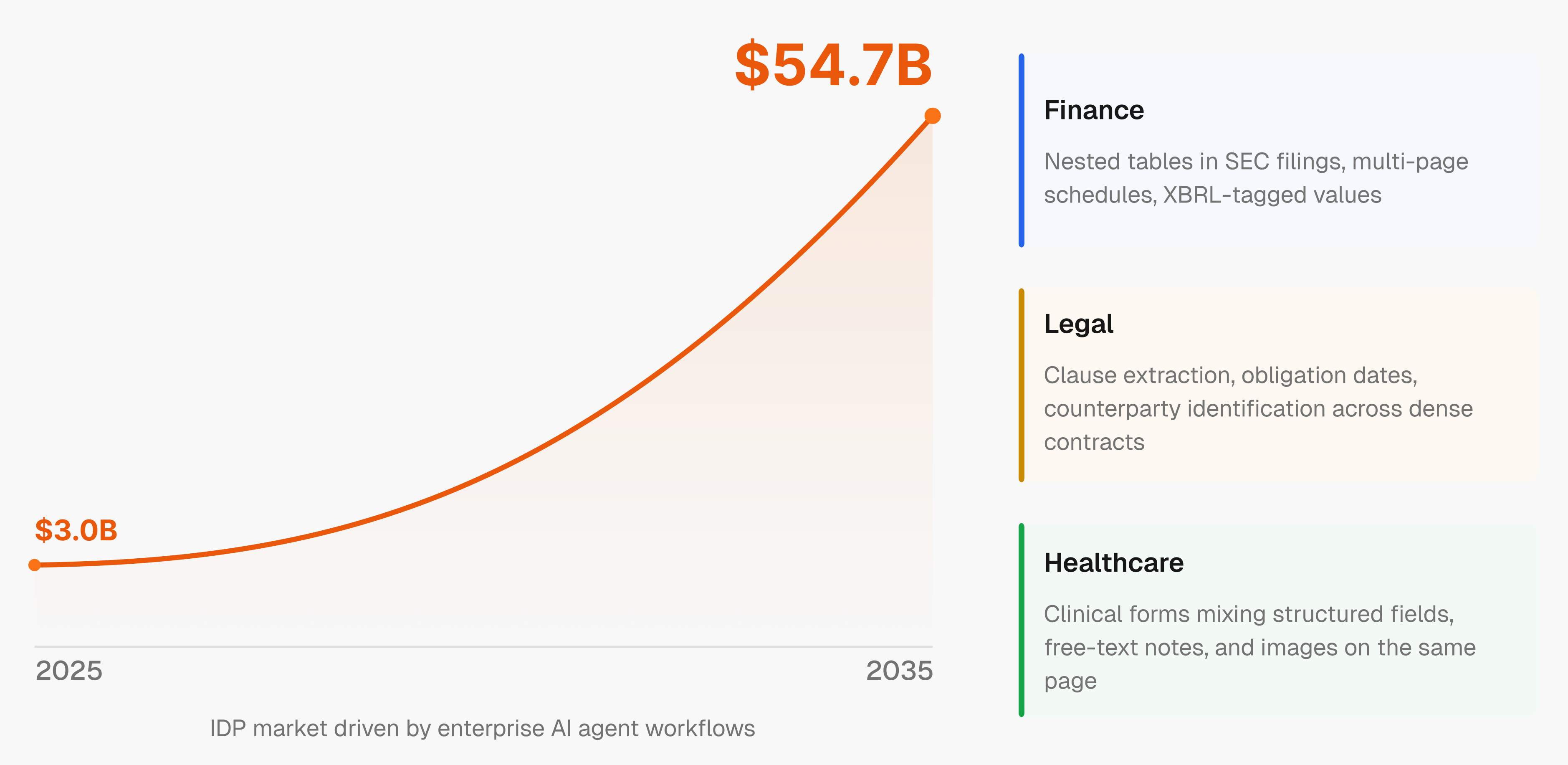
Finance, legal, and healthcare feel this the most. A missed clause in a contract or a misread figure in a regulatory filing isn't a data error. It's a liability.
How We Tested Multimodal Data Extraction Tools
Picking the right multimodal extraction tool is less about feature checklists and more about whether it holds up when your documents get messy. Here's what actually matters in a production context.
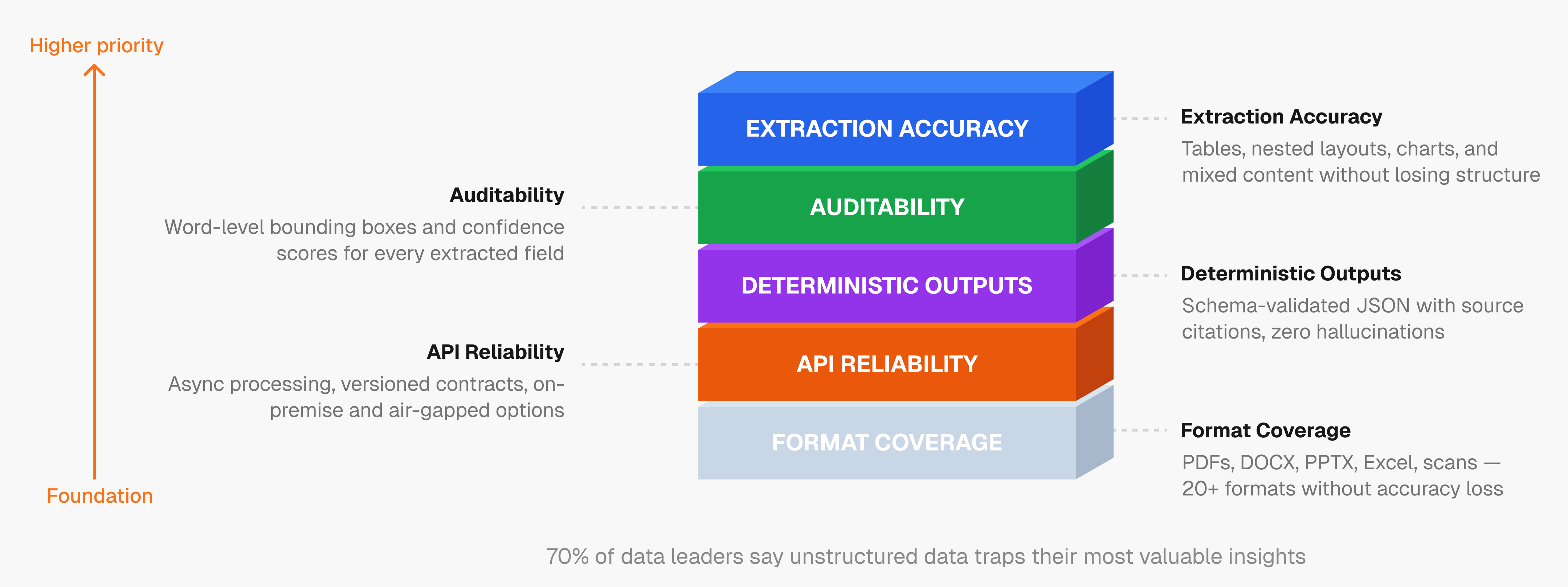
Extraction Accuracy on Complex Content
The baseline is whether a tool can handle tables, nested layouts, charts, and mixed content without losing structure. Generic parsers fail here. We looked for tools that preserve reading order, interpret visual elements correctly, and produce outputs that don't require extensive post-processing before an agent can use them.
Auditability: Confidence Scores and Bounding Boxes
In finance, legal, and healthcare, you need to know where each extracted value came from. Word-level bounding boxes and per-field confidence scores let you trace any output back to its exact location in the source document. Tools that skip this are a liability in compliance-heavy environments.
Format Coverage
Real enterprise document stacks include PDFs, DOCX, PPTX, Excel, scanned images, and more. We focused on tools that cover 20+ file formats without degrading accuracy across them.
Deterministic, Citation-Backed Outputs
Hallucinated or non-deterministic outputs break agent workflows. Structured JSON with schema validation and source citations keeps outputs predictable enough to trust in production.
API Reliability and Deployment Flexibility
Async processing, stable versioned contracts, and predictable error handling separate tools built for scale from those built for demos. Enterprises in compliance-heavy industries often also require on-premise or air-gapped deployment, making that a hard requirement instead of an optional feature.
"70% of data and analytics leaders say unstructured data traps their most valuable insights," according to research cited across the IDP industry.
Best Overall Multimodal Data Extraction Tool: Unsiloed AI
Unsiloed AI was built to solve the problem that generic parsers keep failing at: making complex, multimodal documents reliably readable for AI agents. The company processes millions of pages weekly for Fortune 150 banks, NASDAQ-listed companies, and 10+ YC startups across finance, legal, and healthcare.
What Sets It Apart
The core of Unsiloed AI is a dual-stream vision model that processes both semantic content and structural layout simultaneously, feeding actual image tokens instead of text alone. That distinction matters. When a parser sees a table, a generic LLM-based tool often flattens it or misreads the reading order. Unsiloed's architecture understands the table as a visual object, preserving its structure in the output.
Every extracted field returns with word-level citations, pixel-level bounding boxes, and a confidence score. You can trace any value back to its exact location in the source document, which is non-negotiable in compliance-heavy environments. The extraction API is schema-driven, returning structured JSON with field-level confidence and page references.
Key Strengths
- Consistent outperformance of LlamaIndex, Gemini, Mistral, and Unstructured.io on public benchmarks
- 20+ file formats supported: PDFs, DOCX, PPTX, Excel, scanned images, and more
- Built-in RL pipeline that uses confidence scores for continuous accuracy improvement
- SOC 2 compliant with on-premise and air-gapped deployment options
- Async processing, versioned REST APIs, and predictable error handling at enterprise scale
For teams where a misread figure or missed clause is a liability, Unsiloed AI's vision-first approach and deterministic outputs are what production actually requires.
Hyperscience
Hyperscience positions itself as enterprise AI infrastructure for document automation, often described as a "Kubernetes for IDP." Its Hypercell offering manages workloads across CPUs, GPUs, and multiple model architectures including NVIDIA Blackwell, NVIDIA Nemotron 3, and Google Gemini.
What They Offer
- Inference layering that dynamically balances compute across diverse hardware and model architectures
- Model-agnostic VLM framework with claimed 99% accuracy and 98.5% automation rates
- Document classification, data validation, and workflow automation in a composable setup
Good for large enterprises with dedicated DevOps teams that want control over model orchestration. If your org already runs Kubernetes and wants to assemble its own IDP stack, Hyperscience fits that pattern.
Where it struggles is on unstructured documents without predictable layouts. The architecture assumes enough structure to route and validate reliably. When layouts break from that assumption, accuracy drops. Deployment cycles are also longer than API-first alternatives, requiring upfront configuration before you process a single document in production.
ABBYY
ABBYY introduced its Document AI API in April 2025, bringing decades of OCR expertise into a developer-facing product for intelligent document processing.
Worth considering for teams already in the ABBYY ecosystem who need consistent OCR across standardized, high-volume forms, it offers:
- Precision OCR that preserves logical document structure for AI-ready outputs
- Pre-trained models for KYC, invoice processing, and customs clearance workflows
- An OCR SDK covering ICR, OMR, OBR, and PDF conversion
- Multi-language support and handwriting recognition
The core limitation is structural. ABBYY's approach relies on template-based extraction, so when document layouts shift, templates break and require manual upkeep across varied document types.
LlamaIndex
LlamaIndex offers LlamaParse, a document parsing service built for teams developing RAG pipelines on the LlamaIndex open-source framework.
There are meaningful tradeoffs worth knowing before adopting it for enterprise work.
- Document parsing for 90+ file types, covering embedded images, complex layouts, multi-page tables, and handwritten notes
- Table extraction using LLM intelligence
- Schema-based extraction agents with page citations and confidence scores
- JSON mode and custom parsing instructions for output control
A free tier covering 1,000 pages per day makes it accessible for RAG experimentation. In production, two gaps surface: LlamaParse is cloud-hosted only, excluding compliance-heavy industries requiring on-premise or air-gapped deployment, and it lacks word-level bounding box traceability that finance, legal, and healthcare extraction workflows depend on.
Unstructured
The Unstructured API handles document partitioning across 26+ file formats through a REST API with an accompanying open-source library.
- Partition function that detects file type and routes to format-specific processing
- Table extraction with configurable parameters
- Pre-built connectors for AWS S3, Google Cloud Storage, and Azure Blob
Good for engineering teams needing basic partitioning on predictable PDFs who want open-source flexibility. Where it falls short is on visually complex documents. Unstructured relies on text-only partitioning, so it drops structural and visual information from non-standard layouts, nested tables, or charts. There is no native vision model understanding of hierarchy or multimodal content, so accuracy degrades on the document types that matter most in finance, legal, and healthcare workflows.
Reducto
Reducto builds vision models for document reading, combining specialized vision-language models, traditional OCR, and layout detection into a single parsing system.
- Parse API supporting 30+ file formats including PDFs, Excel, and PowerPoint
- Extraction with pixel-level citations and an edit endpoint for automated form filling
- 99.24% extraction accuracy on clinical SLAs across real patient cases
Teams processing complex legal, financial, and healthcare documents will find Reducto's specialized models handle domain-specific edge cases well. The limitation is scope. Classification, splitting, and schema-based extraction with JSON validation aren't part of the package, so teams end up building those layers themselves before reaching production.
Feature Comparison Table of Multimodal Data Extraction Tools
No single tool wins on every dimension. Here's how the six stack up across the criteria that matter most in production.
Feature | Unsiloed AI | Hyperscience | ABBYY | LlamaIndex | Unstructured | Reducto |
|---|---|---|---|---|---|---|
Vision model architecture | Yes | Yes | No | Yes | No | Yes |
Multimodal content (charts, plots) | Yes | No | No | Yes | No | Yes |
Word-level citations & bounding boxes | Yes | Yes | No | Yes | No | Yes |
Schema-driven extraction API | Yes | Yes | Yes | Yes | No | Yes |
Confidence scores per field | Yes | Yes | No | Yes | No | Yes |
On-premise deployment | Yes | Yes | Yes | No | Yes | No |
Classification & splitting | Yes | Yes | Yes | No | No | No |
20+ file format support | Yes | Yes | Yes | Yes | Yes | Yes |
Deterministic outputs | Yes | Yes | No | No | No | Yes |
For finance, legal, and healthcare teams, gaps in on-premise support, bounding box traceability, and deterministic outputs narrow the field quickly.
Why Unsiloed AI is the Best Multimodal Data Extraction Tool for Enterprise AI Agents
Unsiloed AI closes the gaps that matter in production: vision-first architecture, word-level bounding boxes, schema-driven extraction, deterministic outputs, on-premise deployment, and document classification with splitting, all through a single API.
For AI teams building in finance, legal, or healthcare where a misread value breaks a workflow or creates a compliance risk, that combination is the requirement.
Final Thoughts on Multimodal Data Extraction
The difference between a good structured data API and a generic parser shows up the moment your documents deviate from clean templates. Your finance, legal, or healthcare workflows can't afford extraction that drops tables, misreads charts, or produces outputs you can't trace back to source. Vision-first architecture, deterministic JSON, and deployment flexibility separate tools built for production from those built for demos. Book a demo to see extraction accuracy on your actual document types.
FAQ
Which multimodal extraction tool works best for teams without dedicated DevOps resources?
API-first tools that require minimal configuration before processing documents work best for lean teams. Look for REST APIs with async processing, stable versioned contracts, and predictable error handling that let you start extracting data within hours instead of weeks of deployment planning.
How do I choose between vision-based and OCR-based extraction tools?
If your documents have standard layouts and consistent formats, OCR-based tools handle them reliably. If you process financial statements with nested tables, contracts with complex hierarchies, or any documents where layout changes frequently, vision-based tools that understand structure perform better in production.
Can I verify extraction accuracy before trusting outputs in production workflows?
Yes, by requiring word-level bounding boxes and confidence scores for every extracted field. These let you trace any value back to its exact location in the source document and filter low-confidence outputs before they reach your downstream systems.
What file format coverage do I actually need for enterprise document processing?
Most enterprise stacks include PDFs, DOCX, PPTX, Excel, and scanned images as a baseline. If you process 20+ formats without accuracy degradation, you avoid building separate pipelines for edge case file types that appear less frequently but still require reliable extraction.
When should I choose on-premise deployment over cloud-hosted APIs?
If you operate in finance, legal, or healthcare under regulations that restrict where customer data can be processed, on-premise or air-gapped deployment becomes a requirement instead of a preference. Cloud-only tools eliminate themselves from consideration in those environments.