
Extend Alternatives: Best Document Processing APIs (April 2026)


Looking at Extend alternatives usually means one of two things: you need API-level control over document parsing, or you're working with documents where accuracy requirements go beyond what workflow tools provide. Teams in finance, legal, and healthcare often hit this wall when they need deterministic extraction with confidence scores per field, beyond a final aggregate output. Here's what to consider if you're building document infrastructure that ships to production.
TLDR:
- Extend bundles models and workflows for no-code document processing at 95% accuracy.
- API-first alternatives offer programmatic control and deterministic extraction for production RAG.
- Word-level citations and confidence scores matter for compliance in finance, legal, and healthcare.
- Unsiloed AI delivers air-gapped deployment with dual-stream vision models for complex documents.
- Teams processing SEC filings or loan docs need traceability beyond workflow orchestration.
What is Extend and How Does It Work?
Extend is a document processing solution that bundles models, infrastructure, and tooling into a single offering for end-to-end document workflows. It handles unstructured data across PDFs, images, and emails through workflows that combine LLMs, business logic, integrations, and human in the loop validation with no code required. Teams need to consider how different tools approach accuracy, deployment, and extraction depth when comparing alternatives.
The system supports multiple processing modes covering parsing, classification, extraction, and splitting. Teams can choose low-latency processing for real-time use cases, cost-optimized modes for batch jobs, or high-accuracy modes when precision is non-negotiable. Extend targets teams where accuracy requirements clear 95 percent, making it a serious option for document-heavy pipelines. That said, serious requirements deserve serious comparison shopping, which is exactly what this article is for.
Why Consider Extend Alternatives?
Extend works well for teams that want workflow orchestration with minimal code. But not every team fits that mold.
Engineering teams building production RAG pipelines or custom document ingestion systems often need programmatic control that a no-code workflow layer doesn't provide. API-first infrastructure, schema-driven extraction, and the ability to tune parsing behavior at the component level matter when you're shipping to production.
A few friction points worth noting:
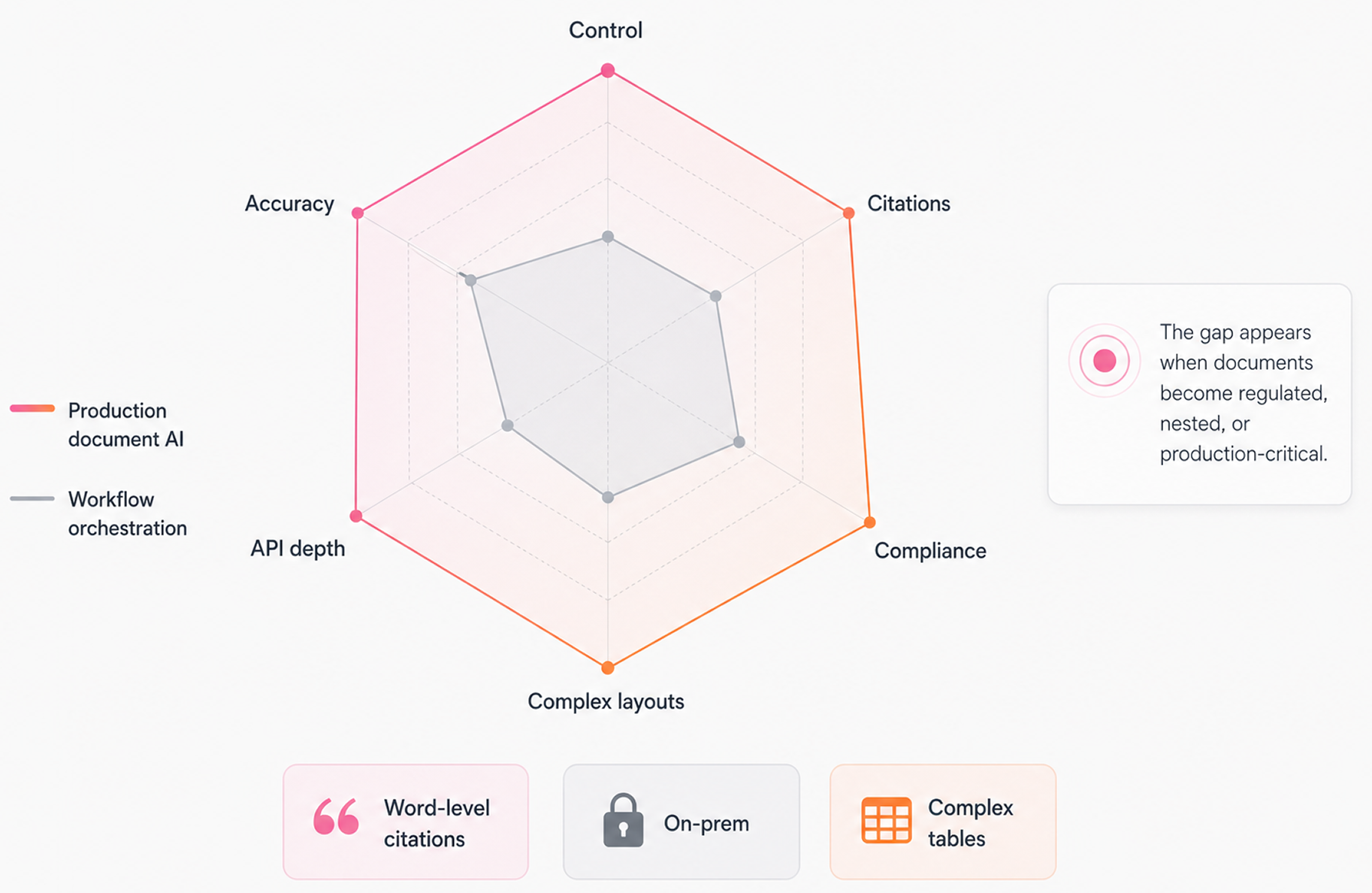
- Finance, legal, and healthcare applications often require deterministic extraction with word-level citations and confidence scores per field, beyond a final aggregate output.
- Organizations under strict compliance requirements (SOC 2, HIPAA, etc.) may need on-premises or air-gapped deployments that cloud-based workflow tools can't support.
- Teams that need vision-aware parsing for complex layouts, nested tables, or non-standard document structures may find that orchestration-first tools sacrifice depth for breadth.
The 95% accuracy threshold Extend targets sounds high until you're processing SEC filings or loan servicing docs where a single misread table cell creates downstream errors. At that point, the question becomes: how does it handle the hard ones?
Best Extend Alternatives in April 2026
Here are the strongest alternatives worth considering for document parsing and extraction workflows in 2026.
1. Unsiloed AI (Best Overall Alternative)
Unsiloed AI provides vision-first, layout-aware APIs for converting complex multimodal documents into deterministic, machine-readable formats. Built for AI teams at Series B+ companies and enterprises, we process millions of pages weekly for Fortune 150 banks, NASDAQ-listed companies, and startups in finance, legal, and healthcare.
- Proprietary dual-stream vision model capturing both semantic content and structural layout simultaneously
- Deterministic extraction with word-level citations, bounding boxes, and confidence scores per field
- Hierarchical indexing with parent-child chunk mapping for RAG pipelines
- On-premise, air-gapped, and hybrid deployment options for compliance-heavy environments
- Python and JavaScript SDKs alongside a REST API with stable versioned contracts
Best for AI and ML engineers building vertical AI products, RAG pipelines, or document-driven automation where errors are costly. Especially relevant for teams working with SEC filings, contracts, clinical records, and loan servicing documents.
The core difference from Extend: Unsiloed is API-first infrastructure, not a no-code workflow tool. You get programmatic control, schema-driven extraction with full traceability, and production-grade deployment flexibility that orchestration products rarely match.
2. Reducto
Reducto is an API for converting documents to RAG-ready outputs, process automation, and related workflows. It combines traditional computer vision with Vision-Language Models to produce LLM-ready output from over 30 document formats, using an Agentic OCR framework that layers correction passes to catch errors base models miss.
- Agentic OCR with multi-pass correction for improved accuracy on complex layouts
- Support for 30+ document formats
- Structured output optimized for RAG and downstream LLM consumption
Best for teams that want an API-driven alternative without heavy workflow orchestration.
3. LlamaParse
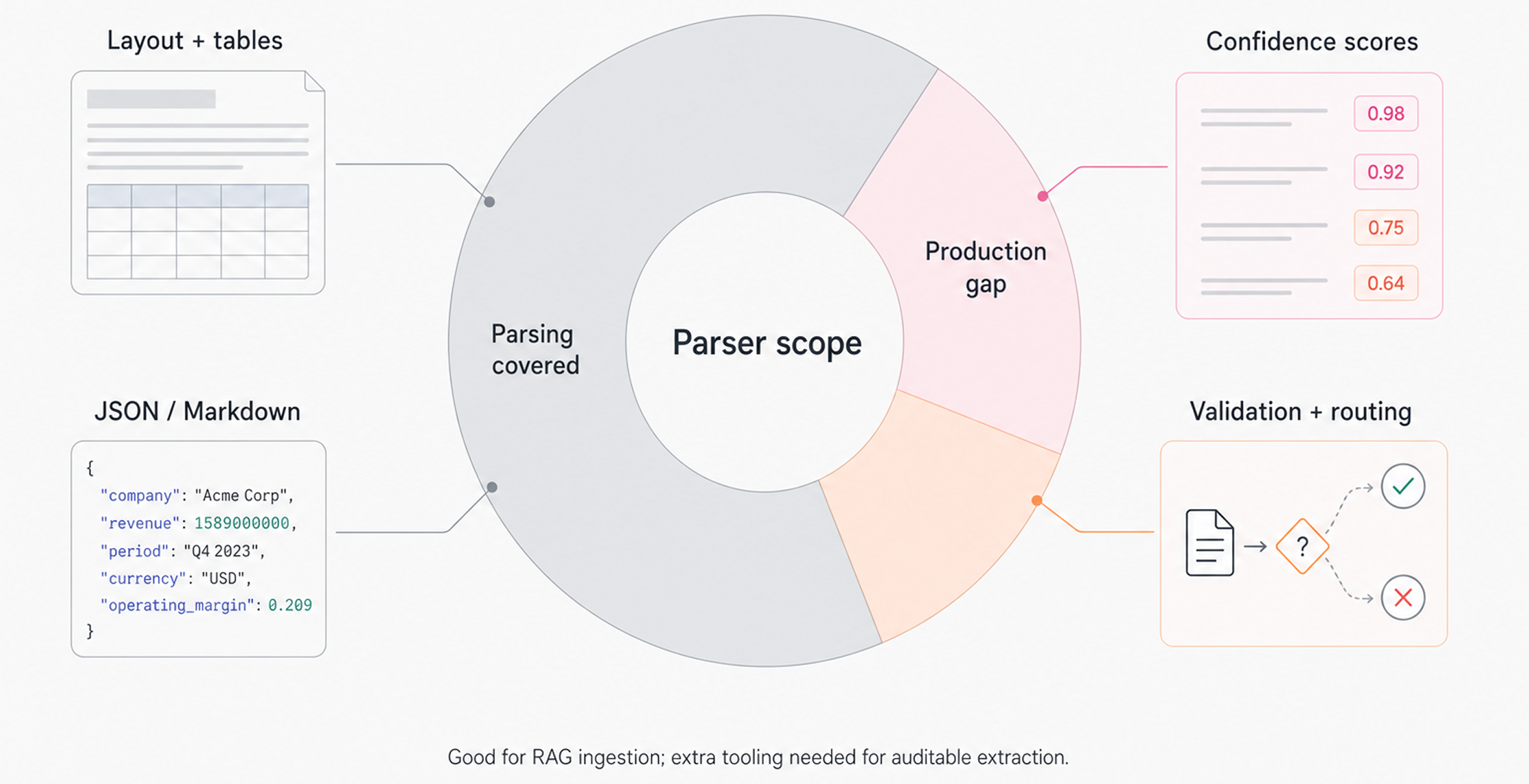
LlamaParse is an AI-native parsing API built by LlamaIndex, focused on reconstructing document structure including sections, hierarchy, tables, and figures. It targets engineering teams building RAG and agentic workflows that need LLM-ready data. The service offers both cloud and on-premise deployment options with SOC 2 Type 2, HIPAA, and GDPR compliance, making it viable for teams with regulatory requirements. LlamaParse provides a free tier of 1,000 pages per day, which gives teams meaningful room to test accuracy on their actual document corpus before committing to paid plans. The API supports JSON and Markdown output modes depending on your downstream pipeline, and integrates directly with LlamaCloud for teams building full ingestion workflows. While it stops at parsing and does not handle validation or confidence scoring, it delivers clean, structured outputs that work well for RAG input preparation when you are already invested in the LlamaIndex ecosystem.
What they offer:
- Parsing API with semantic structure reconstruction for sections, hierarchy, tables, and figures
- Supports multimodal output with text and image extraction from the same document
- Auto-mode and custom parsing instructions for controlling how the parser interprets content
- JSON and Markdown output modes depending on downstream use case
- LlamaCloud integration for building full document ingestion pipelines
- Free tier available up to 1,000 pages per day; paid plans scale from there
Good for teams already in the LlamaIndex ecosystem who want fast, LLM-ready parsing without building a pipeline from scratch. If you're comparing RAG frameworks for production AI, LlamaParse integrates directly with LlamaIndex's retrieval capabilities.
Key limitation: LlamaParse is designed for RAG input preparation, so it stops at parsing. Validation, confidence scoring, and system routing live outside its scope entirely.
Bottom line: If your workflow goes beyond ingestion into structured extraction with auditability requirements, LlamaParse leaves a lot of that work to you.
LlamaParse processes documents by analyzing visual structure and content relationships simultaneously, which lets it handle broken tables, scanned pages, charts, and embedded images more reliably than sequential text readers. The API reconstructs section nesting and table context even when formatting is inconsistent, using semantic understanding of document hierarchy instead of positional heuristics. Custom parsing instructions let you control how the parser interprets specific content types, and auto-mode adapts to common formats without requiring manual configuration per document class. You get both text and image extraction from the same request, with JSON and Markdown output modes that match your downstream pipeline requirements. Deployment covers both cloud and on-premise environments with SOC 2 Type 2, HIPAA, and GDPR compliance, and no customer data is used for model retraining.
There are a few notable capabilities worth considering here:
- Multiple parsing tiers let you balance cost, accuracy, and latency, with auto-routing built in to optimize costs across scalable document processing pipelines.
- 10,000 free credits per month give you room to test the service before committing to a paid plan.
- Cloud or on-premise deployment options come with SOC 2 Type 2, HIPAA, and GDPR compliance, and no customer data retraining.
Good for teams building RAG and automation workflows who want to avoid maintaining custom parsers internally.
Key limitation: Deeply nested financial tables and multi-section reports are a recurring weak spot, often causing missed sections or distorted structure in complex layouts.
Bottom line: The free tier and compliance posture make it worth testing. For complex financial or legal documents, Unsiloed AI's dual-stream architecture and domain-aware decoders consistently produce more accurate outputs, and our true air-gapped deployment support covers environments that this tool simply cannot reach.
4. AWS Textract
AWS Textract offers text detection (basic OCR), document analysis (tables and forms), and specialized queries where you ask natural-language questions about a document. The service targets teams already on AWS infrastructure who need scalable text and table extraction.
What they offer:
AWS Textract covers three distinct capabilities: text detection for raw OCR output, document analysis for structured extraction of tables and form key-value pairs, and a Queries API where you ask a natural-language question about a document and receive a targeted answer with a confidence score. Pricing is per feature and per page, ranging from $0.0015 per page for basic text detection up to $0.05 per page for form extraction, which means a single document passing through multiple features can run $0.08 per page or more. The output is position-aware JSON with hierarchical relationships at the word level, including bounding box coordinates for every detected element. Native integration with S3, Lambda, and the broader AWS ecosystem makes it straightforward to wire into existing AWS pipelines without standing up separate infrastructure. The Queries feature is notable for point-in-document retrieval, useful for pulling a specific field from a form when you already know what you are looking for.
- Text detection at $0.0015 per page, table extraction at $0.015 per page, form extraction at $0.05 per page, and queries at $0.015 per page
- Position-aware text representation with hierarchical relationships down to the individual word level
- Native integration with AWS infrastructure and services
- Queries feature lets you ask questions like "What is the total amount?" and returns the answer with a confidence score
Good for teams already on AWS who need reliable OCR and form extraction at scale with pay-per-use pricing.
Key limitation: Pricing gets complicated fast. Processing a single invoice through the full pipeline can run $0.08 per page, which adds up differently than competitors quoting a flat per-page rate. Textract also returns verbose JSON with nested span references and bounding box metadata, which adds overhead if you just want clean field values.
What they offer:
Unstructured.io provides an open-source Python library and enterprise solution for ingesting and pre-processing unstructured content from over 50 sources including PDFs, HTML, Word documents, and images. The library partitions documents into logical elements like titles, tables, list items, and narrative text while preserving metadata for downstream traceability and lineage tracking. You get a modular ETL pipeline where each document type runs through format-specific processors that extract text, tables, and images before converting them into structured outputs ready for LLM consumption. The enterprise tier adds managed infrastructure with chunking strategies, embedding generation, and table and image enrichment that the open-source version leaves to you. Both deployment paths support connector-based ingestion across cloud storage, databases, and SaaS solutions, giving you flexibility to build around existing data sources without migrating content first.
- Open-source library with an enterprise option for teams that need managed infrastructure
- Chunking, embedding, and image and table enrichment generation through the enterprise tier
- Partially open-source field extraction support
Good for teams that want open-source flexibility with connector-based data ingestion across many sources.
Key limitation: Field extraction is only partially supported compared to full-featured extraction APIs. The open-source library requires substantial configuration and engineering effort to reach production-grade results, and teams still need to build validation, confidence scoring, and accuracy monitoring on top.
Bottom line: Unstructured.io works if you have the engineering bandwidth to build around it.
Feature Comparison: Extend vs Top Alternatives
Feature | Extend | Unsiloed AI | Reducto | LlamaParse | AWS Textract | Unstructured.io |
|---|---|---|---|---|---|---|
Processing approach | No-code workflows | Vision-first APIs, dual-stream | Agentic OCR, multi-pass | Semantic reconstruction | Traditional OCR | Open-source ETL |
Deployment | Cloud only | Cloud, on-prem, air-gapped | Cloud + on-prem option | Cloud or on-prem | AWS cloud only | Self-hosted or cloud |
Deterministic extraction | No | Yes, word-level citations + confidence scores | No | No | Limited | No |
Pricing | Credits-based | Usage-based, pay-as-you-go | From $0.015/page | Tiered, 10k free pages/month | $0.0015-$0.08/page | Free OSS or enterprise |
Developer APIs | Limited, workflow-focused | REST, Python + JS SDKs | REST, Python + Node SDKs | API + LlamaIndex integration | AWS SDK | Python library + API |
Complex documents | Multiple processing modes | Dual-stream + domain-aware decoders | Multi-pass correction | Auto-routing | Forms and tables | Partitioning + metadata |
Compliance | Cloud-based | SOC 2, air-gapped, no data training | SOC 2, HIPAA | SOC 2 Type 2, HIPAA, GDPR | AWS compliance standards | Self-hosted controls |
The most telling gap in the comparison above is the deterministic extraction column. Every other tool returns outputs without field-level traceability. In compliance-heavy industries where an auditor asks "where did this value come from," Unsiloed AI is the only option that gives you a concrete, verifiable answer with word-level citations and confidence scores attached.
Why Unsiloed AI is the Best Extend Alternative
Extend handles a lot well, but its design focuses on workflow orchestration, not extraction accuracy. For teams that need deterministic outputs with field-level traceability, that distinction matters.
Unsiloed AI delivers word-level citations, bounding boxes, and confidence scores on every extracted value. When a compliance officer or auditor needs to trace a number back to its source, that answer is already attached to the output. No other alternative in this list provides that level of traceability.
The infrastructure story matters too. Air-gapped deployments, no customer data used for model training, and SOC 2 compliance cover the requirements that a cloud-only workflow tool simply cannot meet. If you are processing loan documents, SEC filings, or clinical records at scale, get started with Unsiloed AI to see how it handles your hardest documents.
Final Thoughts on Choosing Document Processing Tools
Choosing between Extend alternatives depends on whether you need orchestration or extraction depth. Workflow tools help non-technical teams get started quickly, but API-first infrastructure gives you the control and traceability that production systems actually require. We built Unsiloed AI to solve the accuracy problems that matter when you're processing financial statements, contracts, or clinical records at scale. If that sounds like your workload, book a demo and bring your messiest PDFs.
FAQ
When should you consider moving away from a no-code workflow tool for document processing?
Move to an API-first solution when you need programmatic control over parsing behavior, field-level validation with confidence scores, or deployment in air-gapped environments. No-code tools work well for basic workflows, but production RAG pipelines and compliance-heavy applications require deterministic extraction with full traceability.
What features matter most when comparing document extraction alternatives?
Focus on word-level citations with confidence scores, support for complex layouts like nested tables, and flexible deployment options including on-premise or air-gapped installations. For finance, legal, or healthcare applications, verify that the tool provides deterministic outputs you can trace back to source documents during audits.
How do vision-first parsing models differ from traditional OCR approaches?
Vision-first models process documents by understanding both semantic content and structural layout at the same time, which handles complex formats like multi-section reports or broken tables more reliably. Traditional OCR reads text sequentially and often breaks when layout changes, while vision models adapt to non-standard structures by recognizing document hierarchy visually.
Can I get field-level traceability with most document extraction APIs?
Most extraction APIs return final outputs without showing where each value came from in the source document. Only a few solutions provide word-level citations, bounding boxes, and confidence scores attached to every extracted field, which matters when compliance officers or auditors need to verify data provenance.
What deployment options matter most for compliance-heavy industries?
Look for true air-gapped deployment support, beyond basic on-premise installation that still requires internet connectivity for model updates. Verify that the vendor commits to never using your data for model training and offers SOC 2 compliance at minimum, with HIPAA support if you process healthcare records.