
Document Data Extraction Software: A Technical Comparison for May 2026


When your extraction pipeline returns JSON that looks valid but semantically wrong, the problem usually traces back to layout understanding. A parser might pull every word from a PDF correctly but still fail because it can't distinguish table headers from body rows or reconstruct reading order across columns. PDF data extraction tools that rely on basic OCR hit accuracy limits around 85%, which means every sixth document still needs manual review. The jump to 99% accuracy requires vision-first architectures that understand document structure before attempting extraction, and that difference determines whether you can automate document workflows or just move the bottleneck from data entry to quality control.
TLDR:
- Vision-first extraction architectures reach 95-99% accuracy on complex documents compared to 85-90% for traditional OCR, closing the gap between manual review and full automation
- Schema-based extraction with confidence scoring routes 99% of clear cases directly to downstream systems while flagging edge cases for human review
- Word-level citations and bounding boxes provide pixel-level provenance for every extracted field, making compliance workflows audit-ready without manual cross-referencing
- Layout-aware parsers preserve document hierarchy and reading order across tables, multi-column layouts, and nested structures that flatten under rule-based extraction
- Production APIs process millions of pages weekly with deterministic JSON outputs, asynchronous batch operations, and self-hosted deployment options for compliance-driven industries
What Document Data Extraction Software Actually Does
Document data extraction software converts files that computers can read physically but not interpret semantically into structured, machine-readable outputs like JSON, Markdown, or CSV. A PDF is a display container: it positions pixels on a page but carries no semantic meaning about what those pixels represent. Scanned images, spreadsheets with merged cells, and presentation slides with embedded charts share the same fundamental limitation.
The engineering challenge comes from how real documents are actually structured. A single invoice or contract might combine free-form text blocks, nested tables, logos, and varied layouts across pages. Naive text extraction flattens all of that into an unordered string with no hierarchy. Proper extraction requires a system that can identify element types, preserve reading order, capture spatial relationships, and produce output that downstream AI agents or databases can reliably consume.
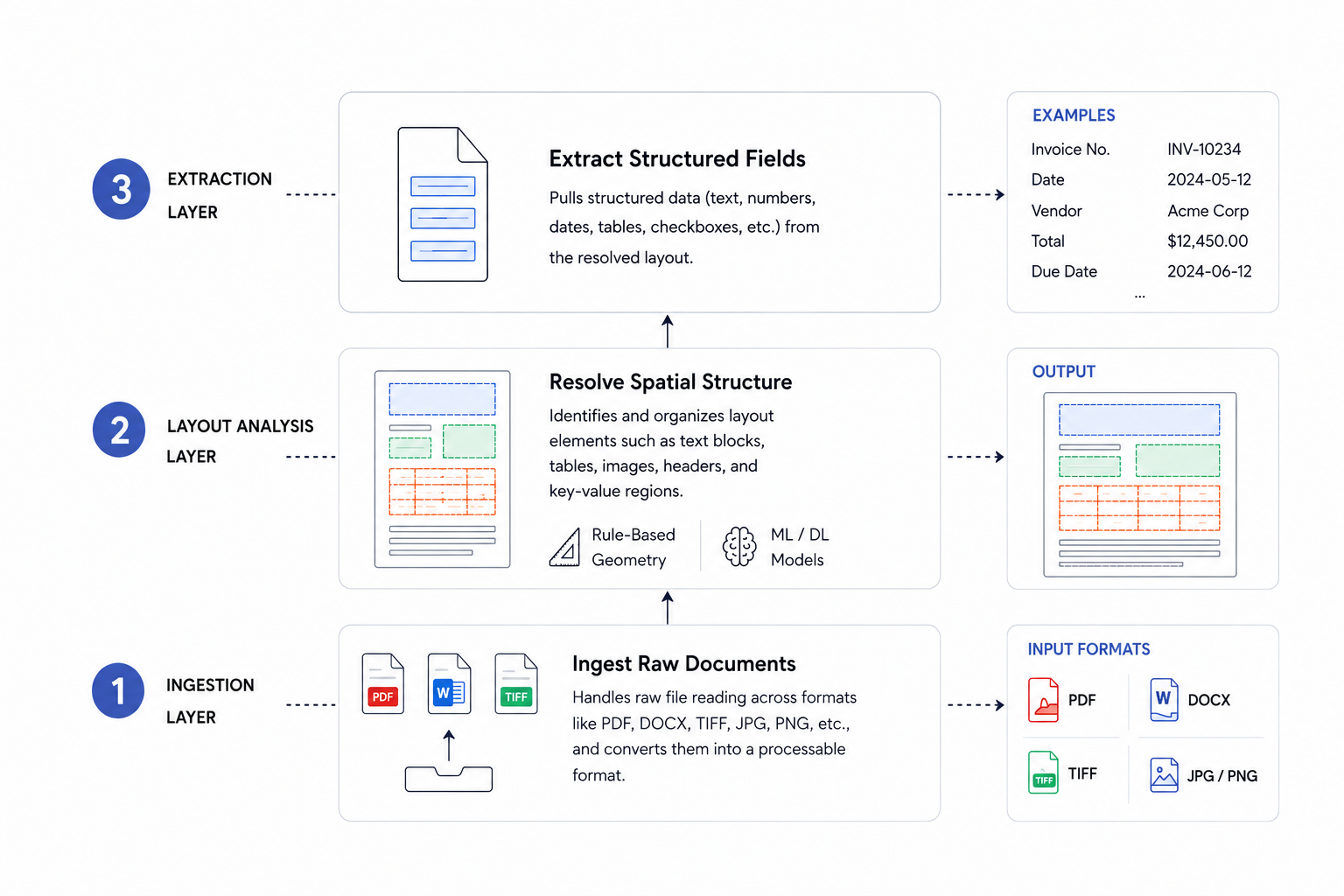
Traditional OCR vs. Vision-First Extraction Architectures
Traditional OCR identifies character shapes pixel by pixel, mapping them to text strings. In clean, printed conditions, this works reasonably well, but accuracy drops sharply with skewed scans, low contrast, or varied fonts. Vision-first architectures process the full page as an image, using AI models trained on document layouts to extract structured data without requiring perfect scan quality.
Feature | Traditional OCR | Vision-First Extraction |
|---|---|---|
Processing Approach | Character-by-character recognition that maps pixel patterns to text strings sequentially | Full-page image analysis using AI models trained on document layouts and spatial relationships |
Accuracy on Clean Documents | 85-90% on printed text with good scan quality and standard fonts | 95-99% across varied document types with preserved layout hierarchy and structure |
Table Extraction Performance | 65% cell-level accuracy, fails on borderless tables and merged cells without manual configuration | 90%+ cell-level accuracy on structured documents, handles borderless tables and multi-row headers |
Multi-Column Layout Handling | Flattens content top-to-bottom, loses reading order across columns and sidebars | Preserves spatial relationships and reconstructs correct reading sequence using bounding box coordinates |
Scan Quality Requirements | Accuracy drops sharply with skewed scans, low contrast, varied fonts, or non-standard layouts | Maintains accuracy across poor scan quality, rotated text, and mixed layouts without perfect conditions |
Processing Speed | Faster per-page throughput with lower computational requirements for simple text extraction | Higher latency per page due to joint encoding, but better throughput on complex documents requiring fewer retries |
Schema-Based Extraction with Confidence Scoring
Schema-based extraction means you define what you want before processing starts. Supply a JSON schema describing the expected output structure, including field names, data types, and descriptions for each field. The extraction engine maps document content to that schema and returns deterministic JSON you can validate programmatically.
Each field returns with a confidence score between 0 and 1. High-confidence fields flow directly into downstream systems, while anything below your threshold routes to a human review queue. Automation handles clear cases; people only see the edge cases worth their time.
API Infrastructure for Production Document Workflows
Production document workflows demand more than browser-based extraction. When you're processing hundreds or thousands of documents, you need programmatic access through a stable API.
Unsiloed AI exposes a REST API that accepts PDF uploads and returns structured JSON, making it straightforward to integrate into existing pipelines. You can trigger extraction jobs, poll for results, and handle errors without leaving your codebase.
For teams assessing docparser api or similar tools, the key questions are rate limits, latency, and schema consistency across document types.
Layout Detection and Reading Order Preservation
Layout detection assigns semantic labels to document regions: headers, paragraphs, tables, figures, footnotes. Reading order reconstruction is where most parsers fail. Two-column layouts, sidebars, and callout boxes create non-linear flows that top-to-bottom text extraction gets wrong.
Vision-first systems use bounding box coordinates to preserve spatial relationships between elements and reconstruct the correct reading sequence. The jump from 85% to 99% extraction accuracy is the automation tipping point. Below it, documents still need manual review. Above it, outputs route directly to downstream systems without human intervention, making audit-ready document workflows viable at scale.
Table Extraction Accuracy Across Parser Implementations
Table extraction is where most PDF parsers fall apart. Merged cells, multi-row headers, and borderless tables consistently trip up rule-based tools, while AI-driven approaches fare better but still vary widely in accuracy.
Research on transformer-based table recognition shows that these systems achieve over 90% cell-level accuracy on structured documents, compared to roughly 65% for heuristic parsers on the same benchmarks.
Key factors that affect extraction quality:
- Cell boundary detection degrades on borderless or lightly-ruled tables where pixel-based methods misinterpret whitespace as column separators.
- Multi-row header parsing requires semantic understanding of row hierarchy, which heuristic tools almost never get right without manual configuration.
- Nested tables in financial or legal documents require recursive parsing logic that most lightweight tools simply skip.
Bounding Boxes and Word-Level Citations
When an extraction API returns a value, the coordinates locating it in the source document matter just as much as the value itself. Bounding boxes provide pixel-level references: left, top, width, and height offsets tied to a specific page. Word-level citations go further, pinning each extracted token to its exact position in the original file.
In compliance-driven industries, auditors need to verify that a clause or dollar figure came from a specific line on a specific page. With provenance baked into the extraction output, human reviewers can jump directly to the source region instead of scanning the full document. Compliance workflows that once required hours of cross-referencing become far more tractable when every extracted field carries its own traceable origin.
Document Classification for Routing and Preprocessing
Before extraction runs, a document needs a type label. Classification assigns one: invoice, contract, receipt, or form. It uses visual layout signals, text patterns, or a combination of both, then routes each type to a dedicated extraction schema with matching validation rules. Wrong classification produces structurally valid but semantically incorrect outputs that fail silently downstream.
Multi-Format Support and Processing Pipelines
Document extraction tools vary widely in the file formats they support. Some tools handle only PDFs, while others accept scanned images, Excel files, Word documents, and HTML. The processing pipeline underneath matters too: a tool relying on basic OCR will struggle with rotated text, low-resolution scans, or multi-column layouts. AI-based processors tend to handle these edge cases better, though accuracy still depends on training data quality.
Structured Data Extraction for RAG and Embeddings
Extraction quality determines retrieval quality. Research shows OCR methods plateau around 0.74 average NDCG@5, a 4.5% absolute gap below perfect text, and complex document layouts compound the problem further. Parsing failures in tables or multi-column sections produce garbled chunks that misrepresent source content. Those errors embed faithfully and degrade semantic search in ways that are hard to diagnose after the fact. Layout-aware parsing with preserved hierarchy is the prerequisite for RAG that consistently returns accurate context.
Processing Speed and Throughput Benchmarks
Processing speed scales with document complexity, page count, and extraction depth. Async architectures decouple job submission from retrieval, so requests queue and run in parallel without blocking callers. Cloud APIs auto-scale under load, while self-hosted deployments require capacity planning before throughput spikes hit.
Vision-Language Models for End-to-End Document Understanding
Vision-language models (VLMs) collapse the discrete OCR-then-layout-then-extraction sequence into a single forward pass, jointly encoding document image and text to generate structured outputs without intermediate representations. Each hand-off in a pipeline-based chain introduces error propagation, so removing those steps matters.
The tradeoff is real. VLMs preserve visual context that OCR discards, which pays off on charts, mixed-layout pages, and borderless tables. But joint encoding is computationally expensive: single-page latency runs higher than specialized OCR pipelines, and throughput drops faster under load. For high-volume workflows, VLMs often work best as a precision layer for complex documents.
Unsiloed AI for Production Document Extraction
Unsiloed AI is designed as the infrastructure layer between raw documents and whatever AI system consumes them. Vision-first models handle 20+ file formats and return hierarchical Markdown and JSON, with word-level citations, bounding boxes, and confidence scores attached to every extracted field. Unlike generic OCR or text-only parsers, the layout-aware approach preserves document structure without hallucinating or flattening hierarchy.
The system processes millions of pages weekly for Fortune 150 banks and NASDAQ-listed companies across finance, legal, and healthcare, where wrong extractions carry real cost. Asynchronous processing and batch operations handle volume at scale, while self-hosted and air-gapped deployment options cover teams where data cannot leave their environment.
Final Thoughts on Building Reliable Document Workflows
Your extraction accuracy determines whether documents route automatically or get stuck in review queues, and document data extraction software that preserves layout and spatial relationships closes that gap. Schema-based extraction with confidence scoring gives you control over what flows through and what needs human eyes. If you're choosing tools for production workflows where wrong outputs carry real cost, book a demo to see how vision-first parsing handles the documents that break rule-based systems.
FAQ
What's the best document data extraction software for production RAG pipelines?
Look for systems that preserve document layout and hierarchy while providing confidence scores for each extracted field. Unsiloed AI processes millions of pages weekly for Fortune 150 banks using vision-first models that handle tables, charts, and multi-column layouts without flattening structure, making it a solid choice for accuracy-sensitive RAG applications.
Can I extract data from PDF without traditional OCR?
Yes. Vision-language models process the entire page as an image and generate structured outputs in a single pass, skipping the discrete OCR-then-layout-then-extraction sequence entirely. This approach handles borderless tables, mixed layouts, and low-quality scans better than character-by-character OCR pipelines.
Docparser alternatives with API access for high-volume workflows?
Unsiloed AI offers REST APIs with asynchronous processing for batch operations, handling 10+ file formats and returning JSON with word-level citations and bounding boxes. The system scales to millions of pages per week with self-hosted deployment options for teams where data can't leave their environment.
How does schema-based extraction improve automation rates?
You define expected output structure using a JSON schema before processing starts, and the extraction engine returns deterministic JSON you can validate programmatically. Fields above your confidence threshold flow directly into downstream systems, while low-confidence extractions route to human review, letting automation handle clear cases and people focus on edge cases.
What accuracy level makes document workflows audit-ready?
The jump from 85% to 99% extraction accuracy is the automation tipping point. Below 85%, documents still need manual review. Above 99%, outputs route directly to downstream systems without human intervention, making compliance workflows in finance, legal, and healthcare viable at scale.


