
Airbyte Alternatives: Best Data Integration Tools (April 2026)


Choosing between Airbyte and its alternatives depends on whether your bottleneck is connector coverage, infrastructure management, or a data type Airbyte wasn't built to handle. The self-hosted version requires ongoing Kubernetes maintenance, the cloud version limits sync frequency to once per hour, and connector reliability varies since most are community-maintained. If you need managed structured data pipelines, alternatives like Fivetran reduce infrastructure overhead. If you're building AI applications that need to parse complex documents, options like Unsiloed AI create structured outputs from PDFs and scanned files where no schema exists. We'll map each alternative to the specific problem it solves best.
TLDR:
- Choose Fivetran over Airbyte when you need 700+ managed connectors without Kubernetes overhead, though MAR-based pricing escalates quickly with high-volume non-relational data.
- Switch to Unsiloed AI when your bottleneck is extracting structured data from PDFs, contracts, or scanned documents - 80% of enterprise data is unstructured and Airbyte can't parse it.
- Use Meltano for configuration-as-code control with 300+ Singer taps if your team treats data pipelines as version-controlled software and owns infrastructure.
- Assess alternatives based on your actual constraint: connector reliability for APIs, infrastructure management burden, or document parsing capability that traditional ELT tools don't provide.
What is Airbyte and How Does It Work?
Airbyte is an open-source data integration tool built for ELT workflows. It helps teams move data from APIs, databases, and files into data warehouses, lakes, and databases for downstream analysis. With over 600 connectors, it covers sources like Salesforce, PostgreSQL, and Google Analytics, and destinations like Snowflake, BigQuery, and Redshift.
The architecture is worth understanding before you assess it. Airbyte loads raw data first, then relies on external tools like dbt for transformations. Orchestration typically runs through Airflow or Dagster. For teams who want flexibility, Airbyte offers self-hosted, cloud, and hybrid deployment options alongside open APIs and a connector development kit.
One thing to keep in mind: only about 15% of source connectors are officially Airbyte-managed. The rest are community-maintained, which affects reliability depending on which connectors your stack actually needs.
Why Consider Airbyte Alternatives?
Airbyte works well for engineering-led teams that want control, but that control comes with real costs.
Self-hosted deployments require Kubernetes expertise and ongoing infrastructure maintenance. As data volume grows, you're managing compute, parallelization, and queue tuning yourself. Without dedicated data engineers, that overhead compounds fast. Airbyte Cloud sidesteps some of that, but introduces its own ceiling: syncs are capped at once per hour, which rules it out for fraud detection, real-time personalization, or anything requiring fresh data on demand. Schema changes can also trigger full re-syncs, disrupting pipelines at the worst possible times.
Connector quality is another variable. Community-maintained connectors make up the bulk of the ecosystem, and reliability varies. Custom connectors require engineering bandwidth to build and maintain, which is a genuine constraint for smaller teams.
There's also a more fundamental gap. Airbyte moves structured data between systems. What it was never built for is unstructured data: PDFs, scanned files, images, complex tables. If you're building AI applications, RAG pipelines, or document automation, you need something that can parse layout, preserve hierarchy, and extract structured data accurately. That's a different problem, requiring a different category of tooling entirely.
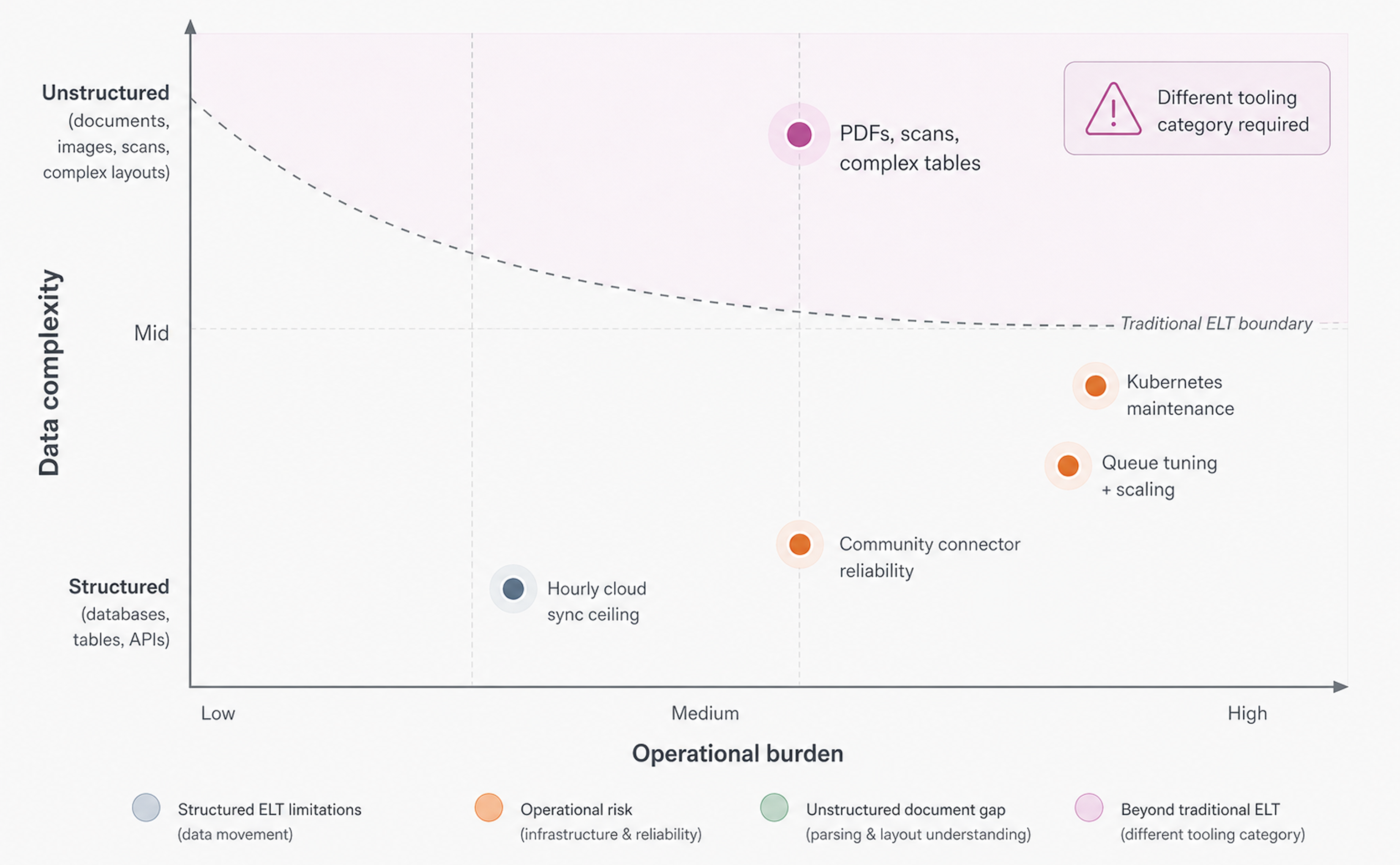
Best Airbyte Alternatives in April 2026
There's no single replacement for Airbyte that fits every team. The right alternative depends on whether your bottleneck is connector coverage, infrastructure overhead, or a data type that Airbyte never handled in the first place.
Unsiloed AI
Unsiloed AI is the unstructured data interface for AI applications. It uses computer vision, OCR, and multimodal models to convert complex documents into deterministic, machine-readable outputs. Where Airbyte moves structured data between systems, Unsiloed AI creates structured data from documents that have no schema to begin with.
Every extracted field comes with word-level citations, bounding boxes, and confidence scores. Outputs are clean Markdown and JSON, built for RAG pipelines and AI agents.
- Parsing API for 20+ file formats, preserving layout, reading order, and visual hierarchy
- Vision-based extraction with confidence scores and bounding box traceability
- Document classification and splitting for routing and batch workflows
- On-premise, cloud, and hybrid deployment with SOC 2 compliance
Good for AI teams in finance, legal, or healthcare processing documents where tables, charts, and layout carry meaning.
Fivetran
Fivetran is a fully managed data integration service with 700+ pre-built connectors. Schema changes are handled automatically, and connector maintenance is owned by Fivetran's engineering team. There's no self-hosting required, which is a real difference from Airbyte.
- Fully managed ELT with automated schema migration
- Pre-built entity relationship diagrams for faster warehouse setup
- Dedicated connector support without community dependency
Good for teams that want Airbyte's connector breadth without the infrastructure burden.
What they offer:
- Over 700 connectors developed in-house, supported by 600+ engineers
- 99.9% uptime guarantee for core services and data delivery
- Automated schema migration and API change handling
- SOC 2 Type 2, PCI-DSS, ISO27001, HIPAA, and GDPR compliance
Good for enterprise teams using cloud warehouses like Snowflake, Redshift, or BigQuery who want a plug-and-play setup with minimal maintenance.
The tradeoff is cost. Fivetran's Monthly Active Rows pricing model can get expensive fast, especially for non-relational data that inflates row counts. Engineers also get limited extensibility since connector releases are vendor-controlled.
Hevo Data
Hevo is a cloud-based ETL/ELT service built for low-code pipeline setup, with options to map sources to targets or add lightweight transformations via Python scripts or a drag-and-drop editor. It launched in 2017 and targets teams that need fault-tolerant, scalable pipelines running with minimal hand-holding.
What they offer:
150+ connectors with 50+ available in the free tier, plus real-time change data capture support and transparent tier-based pricing starting at $239 per month.
Pricing breaks down as follows: a free tier up to 1 million events per month, Starter at $239/month for 50 million events, and Professional at $679/month for 100 million events.
Good for mid-sized businesses and startups that want managed ELT without Fivetran's pricing complexity or Airbyte's infrastructure overhead.
The tradeoffs: cloud-only deployment limits teams with strict data sovereignty needs, and like other ELT tools, Hevo has no capability to process unstructured documents or extract data from PDFs, contracts, or invoices.
Meltano
Meltano started in 2018 as an open-source project inside GitLab, built as a Python framework on the Singer protocol. It takes a modular, CLI-first approach, giving data engineers fine-grained control over every layer of the pipeline.
What they offer:
300+ connectors via Singer taps, configuration-as-code with YAML files version-controlled in Git, and native integration with dbt and Airflow make this a solid choice for data engineers who treat pipelines as software and want full infrastructure ownership.
The tradeoffs: no managed cloud option, ongoing maintenance falls entirely on your team, custom connectors require SDK development work, and there is no support for unstructured data.
Feature Comparison: Airbyte vs Top Alternatives
No single tool wins across every dimension. The table below maps each option by what it actually does, so you can match the right tool to your actual bottleneck.
Feature | Airbyte | Unsiloed AI | Fivetran | Hevo Data | Meltano |
|---|---|---|---|---|---|
Primary use case | Structured data ELT | Unstructured document parsing | Managed ELT | Managed ELT | Developer-first ELT |
Connector count | 600+ | 20+ file formats | 700+ | 150+ | 300+ |
Document parsing | No | Yes (vision-based) | No | No | No |
Layout preservation | No | Yes | No | No | No |
Self-hosted option | Yes | Yes | Limited (hybrid) | No | Yes |
Cloud option | Yes | Yes | Yes | Yes | No |
Transformation support | External (dbt) | Built-in extraction | External (dbt) | Python/drag-drop | External (dbt) |
Confidence scores | No | Yes (word-level) | No | No | No |
Real-time CDC | Yes | N/A | Yes | Yes | Limited |
Open source | Yes | No | No | No | Yes |
Pricing model | Volume/capacity | Usage-based | MAR-based | Event-based | Free (self-hosted) |
Best for | Database/API replication | AI document workflows | Enterprise structured data | Mid-market ELT | DevOps-led teams |
Why Unsiloed AI is the Best Airbyte Alternative
For teams building AI applications, the bottleneck is rarely database replication. It's getting structured, accurate data out of PDFs, presentations, scanned files, and complex tables. This is a problem Airbyte was never built to solve.
80% of enterprise data is multimodal and unstructured. Airbyte moves structured data between systems. Unsiloed AI creates structure where none exists.
The difference shows up in production. Generic LLMs hallucinate on tables and nested layouts. Unsiloed AI uses a vision-first architecture that reads documents the way they were designed to be read, preserving hierarchy, reading order, and layout context. Every extracted value comes with word-level bounding boxes and confidence scores, so you know exactly what was extracted and where it came from.
If your team is processing contracts, financial filings, clinical documents, or any file type where layout carries meaning, Unsiloed AI solves the right problem. Request access to see how it fits your pipeline.
Final Thoughts on Selecting Data Tools That Actually Fit
Most teams comparing Airbyte alternatives realize the problem goes beyond moving data between systems. It's getting clean, structured outputs from documents that have no schema. If you're processing invoices, clinical records, or financial filings where tables and layout matter, you need extraction built for that complexity. Book a demo to see how Unsiloed AI uses computer vision to read documents the way they were designed, with word-level citations and bounding boxes you can trust.
FAQ
When should you consider moving away from traditional ELT tools for document processing?
If your pipeline needs to extract data from PDFs, scanned files, or complex tables, traditional ELT tools won't help. They're built for moving structured data between systems, not creating structure from documents. Teams building RAG pipelines or document automation need parsing tools with vision models, not database connectors.
What features should you focus on when comparing data integration alternatives?
Match the tool to your actual bottleneck. For structured API and database replication, focus on connector reliability and sync frequency. For document-heavy workflows, look for layout preservation, extraction accuracy, and confidence scoring. Deployment model matters too because cloud-only limits teams with data sovereignty requirements.
How do managed services like Fivetran differ from self-hosted options?
Managed services handle connector maintenance, schema migrations, and infrastructure scaling for you, but you lose customization control and pay premium pricing. Self-hosted options like the open-source tools give you full control and lower variable costs, but require Kubernetes expertise and ongoing maintenance bandwidth from your team.
Can I use ELT tools to process unstructured documents for AI applications?
No. ELT tools replicate structured data between systems. They can't parse layout, extract from tables embedded in PDFs, or preserve document hierarchy. For AI applications that need structured data from documents, you need specialized parsing APIs with computer vision capabilities, not database replication tools.
What's the difference between connector count and connector quality?
Raw connector count includes community-maintained options with variable reliability. Check what percentage are officially supported and whether the specific sources you need are vendor-managed or community-built. A smaller set of well-maintained connectors beats hundreds of unmaintained ones that break on schema changes.